使用SAM2获取视频物体连续帧蒙版
最新更新于: 2026年1月12日晚上8点16分
源代码直接clone我fork的SAM2仓库里面就有全部代码,修改视频和图像路径即可使用:wty-yy-mini/SAM2
由于视频中的物体需要进行连续帧打码, 又不能打码过多导致视频展示性降低, 因此尝试通过SAM2框选prompt跟踪掩码的功能来对视频中的物体进行打码, 我的电脑配置如下
- CPU: R7-5700X
- GPU: RTX 4080
- 内存: 50GB
只对原视频中三帧框选需要蒙版的对象即可, 整个视频分割效果如下
最后利用SAM2分割得到蒙版制作频闪摄影效果,用普通的固定位相机录像就可以得到,无需三脚架、快门线、黑色背景、闪光灯等设备:

 |
 |
|---|---|
蓝色渐变code |
冷暖色渐变code |
安装SAM2
推荐安装Conda Miniforge环境: miniforge, 再根据SAM2 GitHub 官方安装流程安装好Pytorch, SAM2, 下载好模型文件, 放到sam2/checkpoints文件夹下:
如果后续运行显存不够, 可以尝试更小的模型文件, 我这里使用的是sam2.1_hiera_base_plus
分割视频
由于SAM2每次需要将整个视频划分为图片, 再一次性全部读入内存中, 并读取全部的prompt, 如果处理的视频时间过长则会显存溢出, 我的显存只有16GB每次只能处理20秒的数据, 下面我们先对视频数据进行处理:
裁剪命令如下, 可以将mp4文件按照20s中所有帧提取到同级目录下的文件夹中, 用于后续处理
python extract_frames_from_video.py --video-file g1_dance_demo.mp4 --folder-duration 20extract_frames_from_video.py源代码如下
# -*- coding: utf-8 -*-
'''
@File : extract_frames_from_video.py
@Time : 2026/01/08 19:49:41
@Author : wty-yy
@Version : 1.0
@Blog : https://wty-yy.github.io/
@Desc : 从视频中按指定时间间隔提取帧并保存为图片存储到对应文件夹中。
python extract_frames_from_video.py \
--video-file g1_dance_demo.mp4 \
--output-folder g1_dance_demo_frames \
--start 2 --end 4 --folder-duration 20
'''
import os
import cv2
import time
from pathlib import Path
from typing import Optional
def extract_frames(
video_path: str,
output_dir: Optional[str] = None,
start: int = 0,
end: Optional[int] = None,
interval_sec: Optional[float] = None,
folder_duration: Optional[float] = None,
folder_prefix: str = "frame",
folder_start_idx: int = 1,
):
"""
从视频中按指定时间间隔提取帧并保存为图片存储到对应文件夹中, 例如:
folder_duration=20, start=0, end=60, 则会创建3个文件夹:
output_dir/
1_frame0-19/
2_frame20-39/
3_frame40-59/
每个文件夹内保存对应时间段的视频帧图片。
Args:
video_path (str): 输入视频文件的路径。
output_dir (str): 保存图片的目标目录, 默认在video_path同级路径下创建同名文件夹。
start (int): 开始时间点 (秒), 默认从0秒开始。
end (Optional[int]): 结束时间点 (秒), 默认到视频结尾。
interval_sec (Optional[float]): 提取帧的时间间隔 (秒), 默认提取所有帧。
folder_duration (Optional[float]): 每个子文件夹包含的视频时长 (秒), 默认不分文件夹。
folder_prefix (str): 子文件夹前缀名称, 默认 "frame"。
folder_start_idx (int): 子文件夹起始索引, 默认从1开始。
"""
if not os.path.exists(video_path):
print(f"[ERROR] Video file {video_path} not found.")
return
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"[ERROR] Can't open video {video_path}.")
return
fps = cap.get(cv2.CAP_PROP_FPS)
if fps == 0:
print("[ERROR] Can't get FPS.")
cap.release()
return
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"Process video: {video_path}")
print(f" - FPS: {fps:.2f}")
if end is None or end > total_frames / fps:
end = total_frames / fps
if output_dir is None:
output_dir = str(Path(video_path).parent / f"{Path(video_path).stem}_frames")
output_dir = str(output_dir) + f"_{int(1/interval_sec) if interval_sec is not None else int(fps)}fps"
output_dir = Path(output_dir)
output_dirs = []
output_dir.mkdir(parents=True, exist_ok=True)
now_save_dir = output_dir / f"{folder_start_idx}_{folder_prefix}{int(start*fps)}-{int(end*fps-1)}"
if folder_duration is None:
now_save_dir.mkdir(parents=True, exist_ok=True)
output_dirs.append(now_save_dir.name)
now_end = None # 当前子文件夹结束时间点 (秒)
# 循环读取和保存帧
frame_count = 0 # 记录总共读取了多少帧
saved_count = 0 # 记录总共保存了多少帧
next_save_time_sec = 0.0 # 下一个保存图片的目标时间点(秒)
use_tqdm = True
try:
from tqdm import tqdm
bar = tqdm(range(0, int(end * fps)), desc="Extracting frames", unit=" frames")
except ImportError:
bar = range(0, int(end * fps))
use_tqdm = False
start_time = time.time()
for _ in bar:
if cap.isOpened():
flag, frame = cap.read()
if not flag:
break
current_time_sec = frame_count / fps
frame_count += 1
if end is not None and current_time_sec >= end:
break
if current_time_sec < start:
continue
# 检查是否达到了保存时间点
if current_time_sec > next_save_time_sec or interval_sec is None:
if folder_duration is not None and (now_end is None or current_time_sec >= now_end):
# 创建新的子文件夹
now_save_dir = output_dir / f"{folder_start_idx}_{folder_prefix}{int(current_time_sec*fps)}-{int(min(current_time_sec+folder_duration, end)*fps-1)}"
output_dirs.append(now_save_dir.name)
now_save_dir.mkdir(parents=True, exist_ok=True)
folder_start_idx += 1
saved_count = 0
now_end = current_time_sec + folder_duration
output_filename = now_save_dir / f"{saved_count:05d}.jpg"
cv2.imwrite(output_filename, frame)
saved_count += 1
if interval_sec is not None:
next_save_time_sec += interval_sec
if not use_tqdm:
if frame_count % int(fps) == 0:
time_used = time.time() - start_time
print(f" - Processed {frame_count}/{total_frames} frames, remaining {int(time_used)}<{int((total_frames - frame_count) / frame_count * time_used)} sec")
cap.release()
print(f"\n处理完成。")
print(f" - 总共读取帧数: {frame_count}")
print(f" - 图片保存至: '{output_dir}'")
print(f" - 包含子文件夹: {output_dirs}")
from argparse import ArgumentParser
parser = ArgumentParser()
parser.add_argument("--video-file", type=str, required=True, help="Path to the video file.")
parser.add_argument("--output-folder", type=str, help="Directory to save extracted frames.")
parser.add_argument("--start", type=int, default=0, help="Start time in seconds.")
parser.add_argument("--end", type=int, help="End time in seconds.")
parser.add_argument("--folder-duration", type=float, help="Duration of each folder in seconds.")
parser.add_argument("--interval-sec", type=float, help="Interval between extracted frames in seconds.")
parser.add_argument("--folder-prefix", type=str, default="frame", help="Prefix for folder names.")
parser.add_argument("--start-idx", type=int, default=1, help="Starting index for folder naming.")
args = parser.parse_args()
extract_frames(
video_path=args.video_file,
output_dir=args.output_folder,
start=args.start,
end=args.end,
folder_duration=args.folder_duration,
interval_sec=args.interval_sec,
folder_prefix=args.folder_prefix,
folder_start_idx=args.start_idx,
)
LabelMe制作prompt
SAM2支持两种prompt: points和boxes, 通过prompt可以给出我们想要分割的目标对象, 在第帧我们给出了分割对象, 后面模型就会自动追踪将其分割出来, 这里我们使用LabelMe来绘制boxes prompt, 这里推荐下载GitHub - LabelMe - v5.5.0可执行文件, 直接运行
LabelMe的配置文件在
~/.labelmerc(Linux),用户目录/.labelmerc(Windows)下, 如果每次启动的配置不符合要求, 可以修改配置文件, 便于下次启动
打开LabelMe, 首先进行配置:
- File -> Save Automatically 打开
- File -> Save With Image Data 关闭
- Edit -> Keep Previous Annotation 关闭
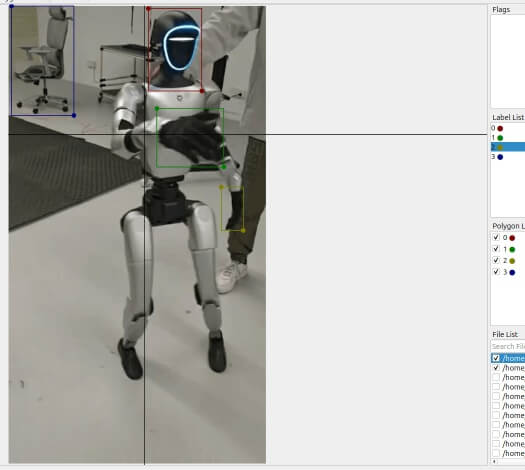
然后点击Open Dir, 打开刚才我们执行完extract_frames_from_video.py得到的数据文件夹g1_dance_demo_frames_30fps/1_frame0-149, 选择矩形边界框如下图所示, 框选出边界即可, 相同目标的label给成相同的, 上下帧会自动对应上(例如我这里就有四个类别0,1,2,3), Ctrl+S保存标记 (由于我们选择了Save Automatically, 切换到其他的图片也能自动保存标记)
| 第0帧 | 第14帧 | 第29帧 |
|---|---|---|
 |
 |
 |
如果第一个标记帧不在第0帧,会自动从标记的第一帧开始生成蒙版,但是千万不要删除没有蒙版的前序帧,这会导致帧顺序错乱。
SAM2蒙版生成
完成上述多帧的prompt标记后, 完成后我们的--video-parent-dir下格式应该为 (这里举个例子)
VID_20251210_094125_frames_30fps # 执行extract_frames_from_video.py后包含每段的分割文件
├── 1_frame450-600 # 分段1
│ ├── 00000.jpg # 分割图片
│ ├── 00000.json # 第一帧必须要有目标框
│ ├── *.jpg
│ ├── 00016.jpg
│ ├── 00016.json # 后续帧蒙版遗漏了可以手动补上框
│ └── ...
├── 2_frame600-750 # 分段2
└── 3_frame750-900 # 分段3运行下面分割代码python sam2_segment_video.py ..., 最后就会在同文件夹下生成每个片段的蒙版视频, 如最上面的视频效果,具体使用说明可以看代码开头的注释部分, 同时保存视频和masks可以得到如下的文件结构
VID_20251210_094125_frames_30fps
├── 1_frame450-600_masked.mp4
├── 1_frame450-600_masks
├── 1_frame600-750_masked.mp4
├── 1_frame600-750_masks
├── 1_frame750-900_masked.mp4
└── 1_frame750-900_masks# -*- coding: utf-8 -*-
'''
@File : sam2_segment_video.py
@Time : 2026/01/08 19:49:22
@Author : wty-yy
@Version : 1.0
@Blog : https://wty-yy.github.io/posts/4856/
@Desc : 用于对视频帧进行SAM2分割并保存分割结果。
clone SAM2仓库并pip install -e .安装后,还需安装 pip install imageio[ffmpeg] matplotlib
首先使用extract_frames_from_video.py (参考blog) 从视频中提取帧并对关键帧对象打框,
然后将该脚本放在SAM2仓库中的tools/目录下,下载SAM2模型
sam2.1_hiera_base_plus.pt 或 sam2.1_hiera_tiny.pt 到checkpoints文件夹中,最后运行本脚本进行分割。
python tools/sam2_segment_video.py \
--video-parent-dir /home/yy/Downloads/VID_20251210_094125_frames_30fps \
--show-prompts \
--save-mask-video \
--save-mask-frames \
--mask-color avg
--video-parent-dir: 包含视频帧文件夹的父目录, 例如 /path/to/video_frames_parent_dir 下有多个子文件夹, 每个子文件夹内包含对应视频的帧图片。
--show-prompts: 是否弹出窗口以显示提示点和边界框的可视化。
--save-mask-video: 是否保存带有分割掩码的视频,保存在`*_masks.mp4`文件夹中。
--save-mask-frames: 是否保存分割掩码的帧图片,保存在`*_masks`文件夹中,蒙版将用(255,255,255)表示,其他均为(0,0,0)。
--mask-color: 用于掩码区域的颜色 ('white'表示白色,'avg'表示使用区域的平均颜色)。
'''
from pathlib import Path
import os
# if using Apple MPS, fall back to CPU for unsupported ops
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
import torch
import json
import imageio
import argparse
import numpy as np
from tqdm import tqdm
from PIL import Image
import matplotlib.pyplot as plt
from typing import Literal
def show_mask(mask, ax, obj_id=None, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
cmap = plt.get_cmap("tab10")
cmap_idx = 0 if obj_id is None else obj_id
color = np.array([*cmap(cmap_idx)[:3], 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=200):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
class SAM2SegmentVideoProcessor:
def __init__(self,
show_prompts=False,
save_mask_video=False,
save_mask_frames=False,
mask_color: Literal['white', 'avg']="white",
):
self.show_prompts = show_prompts
self.save_mask_video = save_mask_video
self.save_mask_frames = save_mask_frames
self.mask_color = mask_color
# select the device for computation
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
print(f"using device: {device}")
if device.type == "cuda":
# use bfloat16 for the entire notebook
torch.autocast("cuda", dtype=torch.bfloat16).__enter__()
# turn on tfloat32 for Ampere GPUs (https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)
if torch.cuda.get_device_properties(0).major >= 8:
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
from sam2.build_sam import build_sam2_video_predictor
sam2_checkpoint = "./checkpoints/sam2.1_hiera_base_plus.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_b+.yaml"
# sam2_checkpoint = "./checkpoints/sam2.1_hiera_tiny.pt"
# model_cfg = "./configs/sam2.1/sam2.1_hiera_t.yaml"
self.predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint, device=device)
self.label2obj_id = {}
self.num_prompts = 0
def init_state(self, video_dir: str):
self.video_dir = Path(video_dir)
try:
self.fps = int(self.video_dir.parent.name.split('_')[-1].replace('fps',''))
except:
self.fps = 30
self.frames = sorted(Path(video_dir).rglob("*.jpg"))
self.w, self.h = Image.open(self.frames[0]).size
print(f"found {len(self.frames)} frames, fps: {self.fps}, frame size: {self.w}x{self.h}")
# Init model
self.inference_state = self.predictor.init_state(video_path=video_dir)
self.predictor.reset_state(self.inference_state)
def load_frame_prompt(self):
""" Find all json files for frame prompts (from LabelMe) """
for frame_json in sorted(self.video_dir.rglob("*.json")):
frame_idx = int(frame_json.stem)
with open(frame_json, "r") as f:
labelme_data = json.load(f)
shapes = labelme_data["shapes"]
if len(shapes) == 0: continue
plt.figure(figsize=(self.w / 100, self.h / 100), dpi=100)
plt.title(f"Frame {frame_idx} with Box Prompts")
plt.imshow(Image.open(self.frames[frame_idx]))
add_infos = {}
for shape in shapes:
if shape['shape_type'] not in ['rectangle', 'point']:
continue
if shape['shape_type'] == 'rectangle':
label = shape['label']
elif shape['shape_type'] == 'point':
label_with_flag = shape['label']
label = label_with_flag.split('_')[0]
point_label = 0 if 'neg' in label_with_flag else 1
if label not in self.label2obj_id:
self.label2obj_id[label] = len(self.label2obj_id)
if self.label2obj_id[label] not in add_infos:
add_infos[self.label2obj_id[label]] = {
'inference_state': self.inference_state,
'frame_idx': frame_idx,
'obj_id': self.label2obj_id[label],
'box': [],
'points': [],
'labels': []
}
infos = add_infos[self.label2obj_id[label]]
if shape['shape_type'] == 'rectangle':
box = shape['points'] # [[x0, y0], [x1, y1]]
x0, y0 = box[0]
x1, y1 = box[1]
box = [min(x0, x1), min(y0, y1), max(x0, x1), max(y0, y1)]
infos['box'].append(box)
show_box(box, plt.gca())
if shape['shape_type'] == 'point':
point = shape['points'] # [[x, y]]
infos['points'].append(point[0])
infos['labels'].append(point_label)
show_points(np.array(point), np.array([point_label]), plt.gca())
if len(add_infos) != 0:
for infos in add_infos.values():
_, out_obj_ids, out_mask_logits = self.predictor.add_new_points_or_box(**infos)
for i, out_obj_id in enumerate(out_obj_ids):
show_mask((out_mask_logits[i] > 0).cpu().numpy(), plt.gca(), obj_id=out_obj_id)
if self.show_prompts:
plt.tight_layout()
plt.axis('off')
plt.show()
else:
plt.close()
self.num_prompts += 1
def segment_frames(self):
if self.save_mask_frames:
output_dir = self.video_dir.parent / f"{self.video_dir.name}_masks"
output_dir.mkdir(exist_ok=True, parents=True)
if self.save_mask_video:
output_video = self.video_dir.parent / f"{self.video_dir.name}_masked.mp4"
writer = imageio.get_writer(output_video, fps=self.fps)
video_segments = {}
if self.num_prompts > 0:
for out_frame_idx, out_obj_ids, out_mask_logits in self.predictor.propagate_in_video(self.inference_state):
video_segments[out_frame_idx] = {
out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
for i, out_obj_id in enumerate(out_obj_ids)
}
for frame_idx in tqdm(range(len(self.frames))):
# Write video
img = Image.open(self.frames[frame_idx])
img = np.array(img)
if self.save_mask_video and frame_idx not in video_segments:
writer.append_data(img)
continue
for out_obj_id, out_mask in video_segments[frame_idx].items():
mask = out_mask.reshape(self.h, self.w)
pixels = img[mask].astype(np.float32)
if len(pixels) > 0:
if self.mask_color == 'avg':
img[mask] = np.mean(pixels, axis=0).astype(np.uint8) # color the masked area with mean color
elif self.mask_color == 'white':
img[mask] = 255 # white out the masked area
if self.save_mask_video:
writer.append_data(img)
# Save segmented frames
if self.save_mask_frames:
mask = np.zeros_like(img)
for out_obj_id, out_mask in video_segments[frame_idx].items():
mask[out_mask.reshape(self.h, self.w)] = 255
output_path = output_dir / f"{frame_idx:05d}.jpg"
Image.fromarray(mask).save(output_path)
# Matplotlib visualization (optional)
# plt.figure(figsize=(self.w / 100, self.h / 100), dpi=100)
# plt.title(f"Frame {frame_idx}")
# plt.imshow(Image.open(self.frames[frame_idx]))
# for out_obj_id, out_mask in video_segments[frame_idx].items():
# show_mask(out_mask, plt.gca(), obj_id=out_obj_id)
# plt.axis('off')
# output_path = output_dir / f"{frame_idx:05d}.jpg"
# plt.savefig(output_path, bbox_inches='tight', pad_inches=0)
# plt.close()
writer.close()
print(f"Segmented video saved to: {output_video}")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--video-parent-dir", type=str, default="", help="Path to the parent of video frames directory.")
parser.add_argument("--show-prompts", action="store_true", help="Whether to show prompts visualization.")
parser.add_argument("--save-mask-video", action="store_true", help="Whether to save masked video.")
parser.add_argument("--save-mask-frames", action="store_true", help="Whether to save masked frames.")
parser.add_argument("--mask-color", type=str, default="white", help="Color to use for masking (e.g., 'white', 'avg').")
args = parser.parse_args()
show_prompts = args.show_prompts
video_parent_dir = args.video_parent_dir
save_mask_video = args.save_mask_video
save_mask_frames = args.save_mask_frames
mask_color = args.mask_color
kwargs = {
"show_prompts": show_prompts,
"save_mask_video": save_mask_video,
"save_mask_frames": save_mask_frames,
"mask_color": mask_color,
}
video_dirs = [x for x in sorted(Path(video_parent_dir).glob("*")) if x.is_dir()]
for video_dir in video_dirs:
idx = int(video_dir.name.split("_")[0])
if 'masks' == video_dir.name.split('_')[-1]:
continue
if idx >= 1:
# if 2 <= idx <= 9 and idx not in []:
sam2_segment_video_processor = SAM2SegmentVideoProcessor(**kwargs)
print(f"Processing video directory: {video_dir}")
sam2_segment_video_processor.init_state(str(video_dir))
sam2_segment_video_processor.load_frame_prompt()
sam2_segment_video_processor.segment_frames()
频闪摄影效果图片制作
有了上述的蒙版, 假如要做出同一张图下的连续残影移动(频闪摄影), 效果图如下
原理非常简单, 只需要找到想要的几帧作为虚影, 再将其中的关键帧高亮出来即可, 下面代码前25行逐行进行对应配置即可
# -*- coding: utf-8 -*-
'''
@File : image_trajectory.py
@Time : 2026/01/08 20:32:07
@Author : wty-yy
@Version : 1.0
@Blog : https://wty-yy.github.io/posts/4856/
@Desc : 在视频帧序列中叠加轨迹蒙版以生成频闪摄影效果图像。
'''
from PIL import Image
import numpy as np
base_dir = "./tools/VID_20251210_094125_frames_30fps" # 视频裁剪主文件夹
origin_image_dir = f"{base_dir}/1_frame450-659" # 原始图像文件夹
mask_dir = f"{base_dir}/1_frame450-659_masks" # 分割掩码文件夹
base_image = f"{base_dir}/base_image.png" # 基础背景图像, 后续在此基础上叠加蒙版
trajectory_idxs = [54, 72, 84, 94, 96, 109, 125, 133, 140, 152, 178, 192] # 轨迹帧索引 (包含虚影和关键帧)
# 颜色定义
TAB_BLUE = np.array([31, 119, 180], dtype=np.uint8)
TAB_ORANGE = np.array([255, 127, 14], dtype=np.uint8)
TAB_GREEN = np.array([44, 160, 44], dtype=np.uint8)
TAB_RED = np.array([214, 39, 40], dtype=np.uint8)
TINT_STRENGTH = 0.6 # 颜色叠加强度
key_idx_color_map = { # 关键帧索引到颜色的映射
192: TAB_GREEN, # Resumed Gait (恢复行走)
133: TAB_RED, # Impact Absorption (冲击吸收)
109: TAB_BLUE, # Rapid Adaptation (快速适应)
96: TAB_ORANGE, # Support Loss (支撑丢失)
54: TAB_GREEN, # Steady-state Gait (稳态行走)
}
def get_img_and_key(idx):
mask_path = f"{mask_dir}/{idx:05d}.jpg"
origin_image_path = f"{origin_image_dir}/{}.jpg"
mask = np.array(Image.open(mask_path).convert("L"))
mask = mask > 200 # 边缘有些噪声, 加大mask阈值可以消去这些
origin_image = np.array(Image.open(origin_image_path).convert("RGBA"))
return origin_image, mask
result_image = np.array(Image.open(base_image).convert("RGBA"))
print("Processing trajectory frames (ghosts)...")
for i, traj_idx in enumerate(reversed(trajectory_idxs)):
origin_image, mask = get_img_and_key(traj_idx)
if traj_idx not in key_idx_color_map:
result_image[mask] = origin_image[mask] * 0.4 + result_image[mask] * 0.6
print("Processing key frames with coloring...")
for key_idx in reversed(key_idx_color_map.keys()):
origin_image, mask = get_img_and_key(key_idx)
target_color = key_idx_color_map.get(key_idx)
robot_pixels_rgba = origin_image[mask]
robot_rgb = robot_pixels_rgba[:, :3]
robot_alpha = robot_pixels_rgba[:, 3:4]
color_overlay = np.full_like(robot_rgb, target_color)
tinted_rgb = (robot_rgb * (1 - TINT_STRENGTH) + color_overlay * TINT_STRENGTH).astype(np.uint8)
tinted_rgba = np.concatenate([tinted_rgb, robot_alpha], axis=1)
result_image[mask] = tinted_rgba
result_image = Image.fromarray(result_image)
result_image.save(f"{base_dir}/result_image.png")
print(f"Result image saved to {base_dir}/result_image.png")
其他渐变色请参考代码
|
|
|---|---|
蓝色渐变code |
冷暖色渐变code |