2024开悟智能体比赛(海选赛)
最新更新于: 2025年8月8日下午3点06分
已结束的全部比赛代码:GitHub - 海选赛全部代码,GitHub - 学习期全部代码
下文主要介绍了本次比赛对源码的学习,由于是第一次参赛,对整个框架比较陌生,所以简单介绍下我通过学习源码对分布式框架逻辑的理解,以及如何在此基础上完成一个PPO算法。
重返秘境
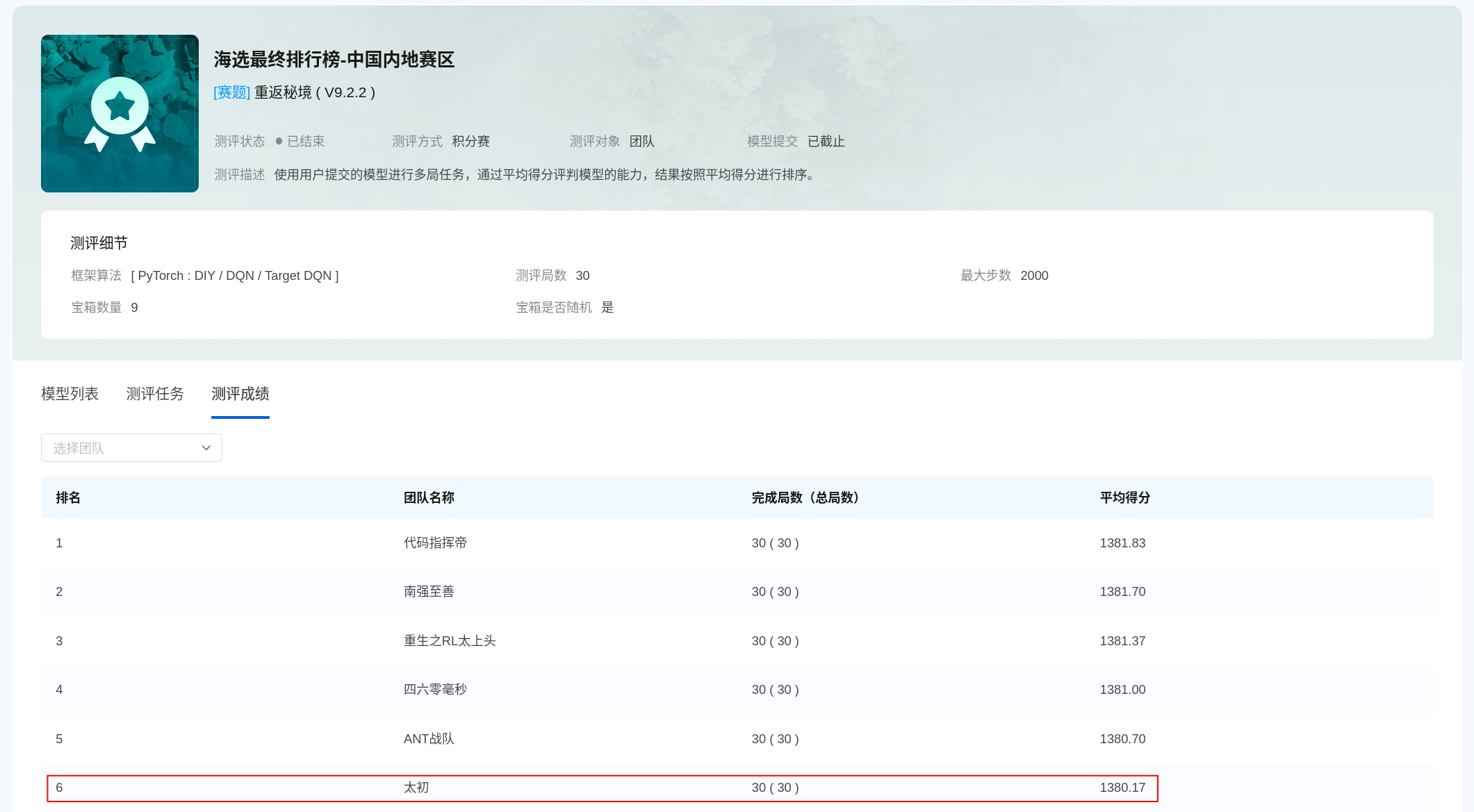
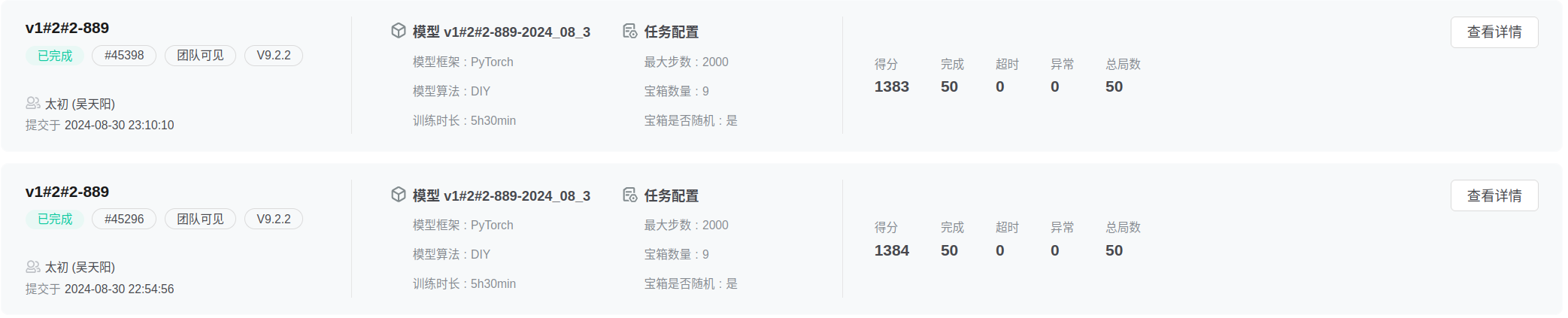
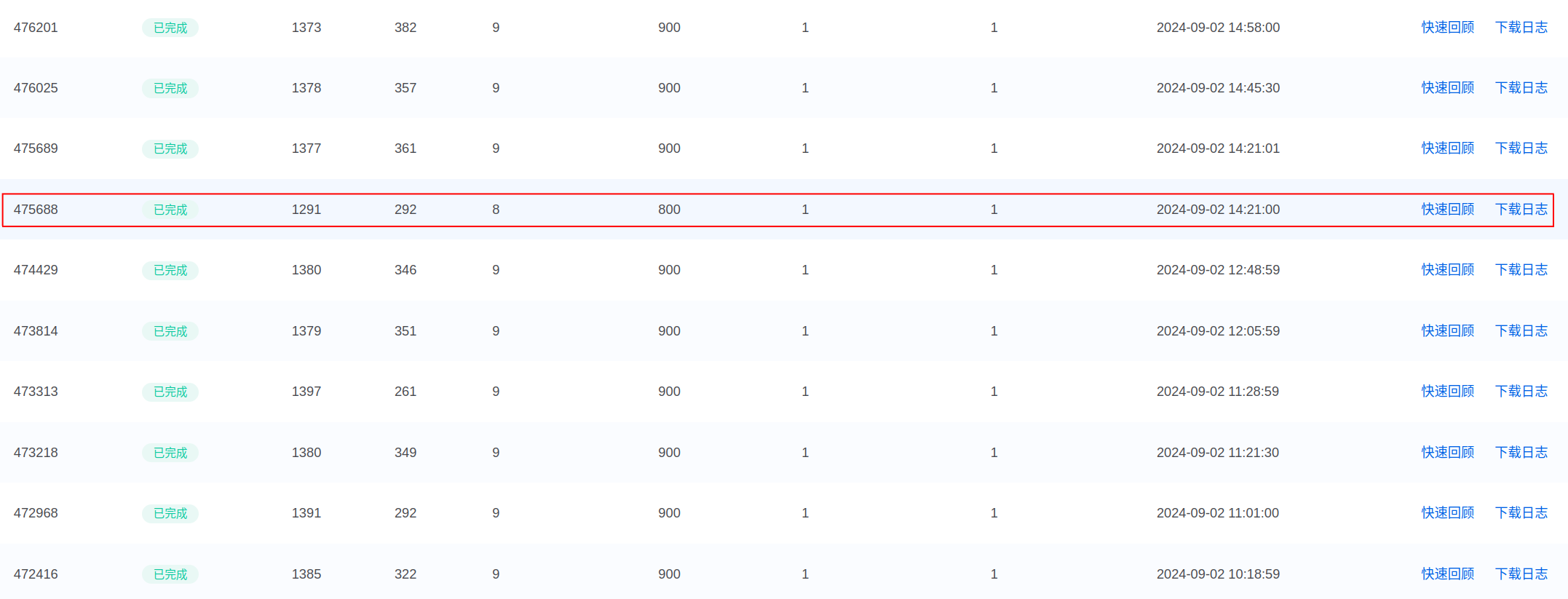
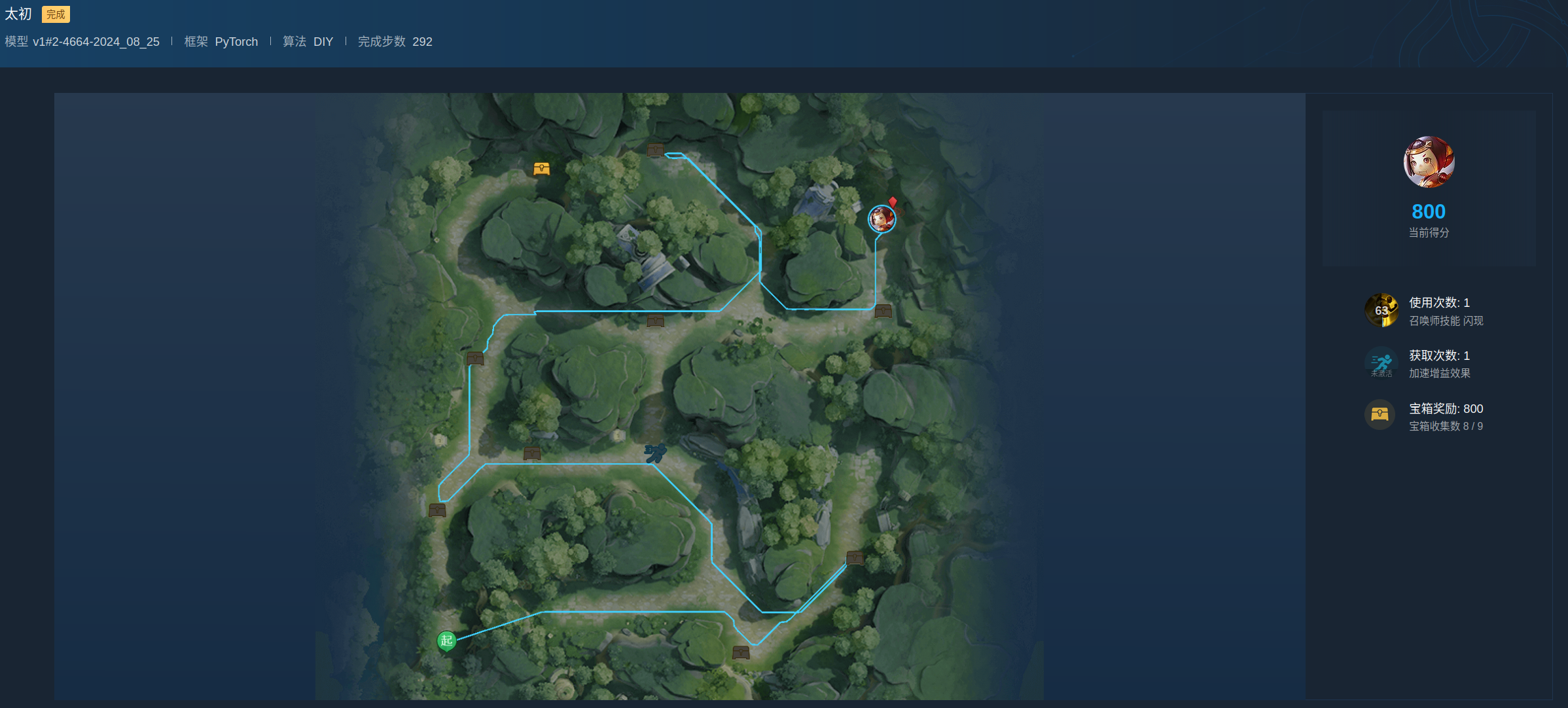
该比赛排名第6(1380.17分,尽管在自己测试300局中平均得分为1383分),第一名1381.83分,失败的主要原因是30次评测中(总共9个随机宝箱),其中有一次评测中只捡了8个,否则可以超过第一名1分以上,只能说智能体还是不够稳定,测试方法不够好(总共也就715种宝箱分布情况,没有全部考虑到),奖励设计还是问题,宝箱遗漏的负惩罚仍然不够大。
PPO算法可以在上述源码中diy文件夹下找到,v1.2的训练总时长为33+20+31.5+12.5=97小时(8~12进程)效果如下图所示,训练12.5小时已经能达到1350分了。

代码基础框架和学习期相同,本次难点在于分布式框架的使用,由于我不喜欢用DQN,只能尝试写PPO
前置芝士
下文中所有的配置参数,若无特殊说明,默认在 conf/configure_app.toml 中,如果没有对应变量名,则需要自己加入(toml语法可以参考官网,可以在vscode中安装toml插件进行渲染)
这里的智能体代码我们都已 diy 中的为例,代码结构如下(必要部分):
└── code
├── conf
│ │ # 自定义的配置文件,也是最高优先级,可以覆盖他们的默认配置
│ └── configure_app.toml
└── diy
├── algorithm
│ │ # 我们定义的智能体Agent类,必须有他们要求的6个函数
│ │ # __init__, predict, exploit, learn, save_model, load_model
│ └── agent.py
├── feature
│ │ # 对SampleData, ObsData, ActData,
│ │ # observation_process, action_process, sample_process,
│ │ # SampleData2NumpyData, NumpyData2SampleData进行定义,
│ │ # 定义并转换存入buffer的数据结构
│ └── definition.py
│ # 配置文件,
│ # 必须保证Config类中的SAMPLE_DIM
│ # 和NumpyData2SampleData函数数据对齐,否则可能报样本维度错误
├── config.py
│ # 模型训练时会调用的训练工作流,用于样本的采样与buffer存入
└── train_workflow.py实现了这些内容后,有两种启动单进程训练的方法(用于调试):
- 将
train_test.py中设置为algorithm_name = "diy"执行train_test.py就可以训练了。 - 将
configure_app.toml中的参数设置为algo = "diy",执行./tools/start.sh即可开始训练。
执行 ./tools/stop.sh all 可以杀死所有进程。
local/remote训练逻辑
两种训练模式local/remote,这关系到进程的创建数目(海选赛和学习期的不同之处),也正如官方所说的,确实可以做到了两种模式下,代码都可以直接运行,最大区别在于local不存在buffer,而remote会创建一个buffer存储aisrv产生的样本。
下面的逻辑分析都是通过查看源码获得,分析方法主要是基于Python中的traceback函数,自己写了一个打印回调信息的函数
show_debug,对源码中的每个部分分别加入该函数进行调试。逻辑分析的过程请见code_logic.md,里面有更详细的调用关系,以下内容为精简版。
用drawio简单画了个示意图(画的挺烂的😟),对每个部分的详细介绍请见下文
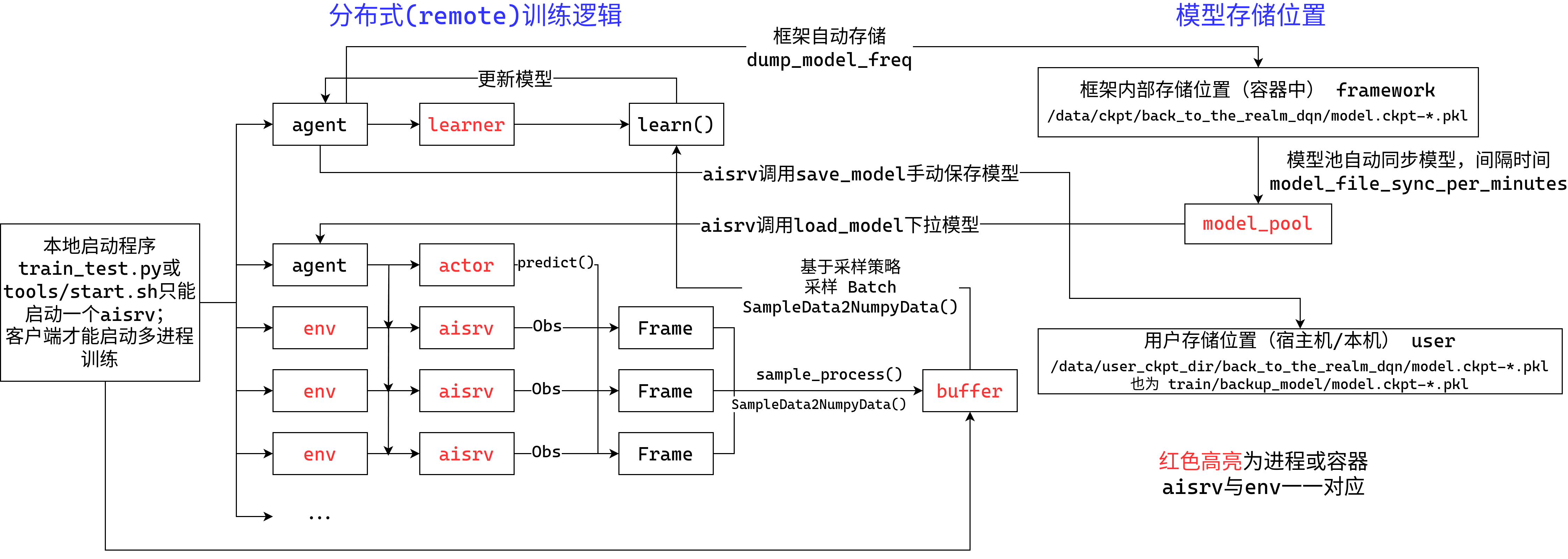
local/remote训练模式:配置参数 wrapper_type 即可对其进行修改,有两个配置:
"local":也就是学习期的本地训练,该模式下,系统不会对你的Agent进行包装,仅包含一个训练进程aisrv,也就是RL最简单的训练模式,初始化环境、智能体、buffer,通过智能体与环境交互获得样本存储在buffer中,训练时从中进行采样,更新value和policy网络。"remote":也就是海选赛的多进程训练模式,该模式下,系统会创建如下几个进程:- learner:
- 功能:用于处理buffer中采样的样本,更新value和policy网络,保存网络参数。
- 介绍:包含一个实例化的
agent。该进程只会调用agent.learn函数,且调用该函数不受我们写的代码控制,仅根据配置中的buffer逻辑进行后台进行自动调用,参考下文中buffer的介绍。 - 注意:在
learn中调用save_model函数只会将模型保存到本机。
- actor:
- 功能:基于状态进行探索动作的预测,并会自动从
model_pool中更新模型参数。 - 介绍:包含一个实例化的
agent。该进程只会调用agent.predict, load_model,这个函数输入的状态信息是由aisrv通过tcp发送到该进程的(如果每个环境都单开一个非常容易导致显存爆炸,并且分布式下也不一定所有服务器都有显卡),因此所有的aisrv都共享的是一个相同的agent实例,该agent的权重更新会用到model_pool,此逻辑会在下文进行介绍。
- 功能:基于状态进行探索动作的预测,并会自动从
- aisrv:
- 功能:使用
actor中的agent与一个独立的环境进行交互,产生样本保存到buffer中。 - 介绍:包含一个实例化的环境
env,该进程会调用train_workflow.workflow函数。注意传入的agent不是你写的Agent类实例化结果,而是actor的,调用所有predict, load_model函数都会通过tcp和actor进行通讯,而learn函数则不会起到作用(由后台根据采样逻辑进行采样并发送learner训练),发送样本到buffer的函数则是learn。
- 功能:使用
- buffer:
- 功能:存储aisrv通过
learn发送的样本,并基于采样策略进行采样。 - 介绍:包含一个从
reverb包(Deepmind)中实例化的buffer。因此buffer的采样和移除策略可以参考官方文档,常用的采样策略为均匀采样Uniform,移除策略为顺序移除(可以把他想象成一个队列,加入样本就是进队尾,顺序移除就是弹出队首),这个配置相关参数为reverb_remover, reverb_sampler。
- 功能:存储aisrv通过
- model_pool:
- 功能:自动同步learner保存的模型(保存频率为配置中的
dump_model_freq,同步时间为model_file_sync_per_minutes,单位分钟),处理actor或aisrv通过load_model进行读取模型的请求。 - 介绍:同步learner保存的模型仅能从框架基于
dump_model_freq自动保存的位置进行读取(保存到上图右上角framework存储位置),也无法手动进行同步,只能通过配置指定的同步时间model_file_sync_per_minutes自动进行同步(由于他还进行了取整处理,因此最小同步时间为1分钟)。 - 注意:model_pool和保存在本机
train/backup_model的模型不同,model_pool是存储到容器中的,而后者是存储在本机的挂载目录下(也就是宿主机)。
- 功能:自动同步learner保存的模型(保存频率为配置中的
- learner:
分布式的启动方法我估计是客户端写了docker compose配置文件,通过compose功能同时开了多个容器(更多的env和aisrv进程)使他们之间用tcp通讯,还没研究这块具体是怎么做到的。。。
PPO的具体实现细节
在GitHub中也记录了当初实现PPO注意的细节
这里大部分把之前论坛回复的内容copy了一些😅
主要就是把gae放到learner中算(得到return和adv), buffer中每个样本存的是一段轨迹, 而logprob使用的是actor采样时候的值, buffer的修改,请见 definition.py:
SampleData = create_cls("SampleData", obs=None, actions=None,
rewards=None, dones=None, next_obs=None, next_done=None,
logprobs=None)
@attached
def NumpyData2SampleData(data): # buffer中取出来以后转换
n = args.num_steps # 我设的是128, 就是存储到buffer中的一小段轨迹长度
obs_dim = args.obs_dim
return SampleData(
obs=data[:n*obs_dim].reshape(n, -1),
actions=data[n*obs_dim:n*(obs_dim+1)],
rewards=data[n*(obs_dim+1):n*(obs_dim+2)],
dones=data[n*(obs_dim+2):n*(obs_dim+3)],
logprobs=data[n*(obs_dim+3):n*(obs_dim+4)],
next_obs=data[n*(obs_dim+4):-1],
next_done=data[-1],
)configure_app.toml 配置文件做的修改如下(大概率不是最优的,没有进行微调):
# 注: learner_train_by_while_true 在9.2.2最后一次更新后就只能设置为True才能使用(不清楚为什么,单机模式下没有测出问题),
# 也就是只能定时训练,那么只能自己手动计算一个样本产生所用的时间,
# 再调整learner_train_sleep_seconds为10个样本生成所需的时间(非常麻烦)
learner_train_by_while_true = false # 关了这个production_consume_ratio才有用
replay_buffer_capacity = 120 # process * 10
preload_ratio = 2 # 当buffer中存在replay_buffer_capacity/preload_ratio个样本时,开始训练,(也要要求learner_train_by_while_true=False)
train_batch_size = 36 # learner训练批处理大小限制, process * 3
production_consume_ratio = 3 # 消耗/生成比
reverb_sampler = "reverb.selectors.Uniform"
dump_model_freq = 2 # PPO要求actor和learner模型差距不能太大, 提高同步模型的保存频率
model_file_sync_per_minutes = 1 # 这个是模型同步到模型池的同步时间 (单位分钟, 最小1min)最后为了避免存储的模型太多导致内存爆炸,我写了个自动删除旧模型的函数,在learner和aisrv中周期性调用。
from pathlib import Path
from kaiwudrl.common.config.config_control import CONFIG
def clean_ckpt_memory():
"""
Remove old checkpoints generate by autosave (save frequency=CONFIG.dump_model_freq),
you can find autosave code at
`kaiwudrl.common.algorithms.standard_model_wrapper_pytorch.StandardModelWrapperPytorch.after_train()`
Usage: Call this function in `agent.learn(...)` or `train_workflow.workflow`,
recommend in `agent.learn(...)` since it is a single process,
add small delay as you like~~~
"""
path_tmp_dir = Path(f"{CONFIG.restore_dir}/{CONFIG.app}_{CONFIG.algo}/")
files = sorted(list(path_tmp_dir.glob('model.ckpt-*')), key=lambda x: int(str(x).rsplit('.', 1)[0].rsplit('-', 1)[1]))
if len(files) < 2: return
for p in files[:-1]: # just keep latest checkpoint
p.unlink()详细代码请见diy/文件夹,PPO算法参考的是cleanrl - PPO。
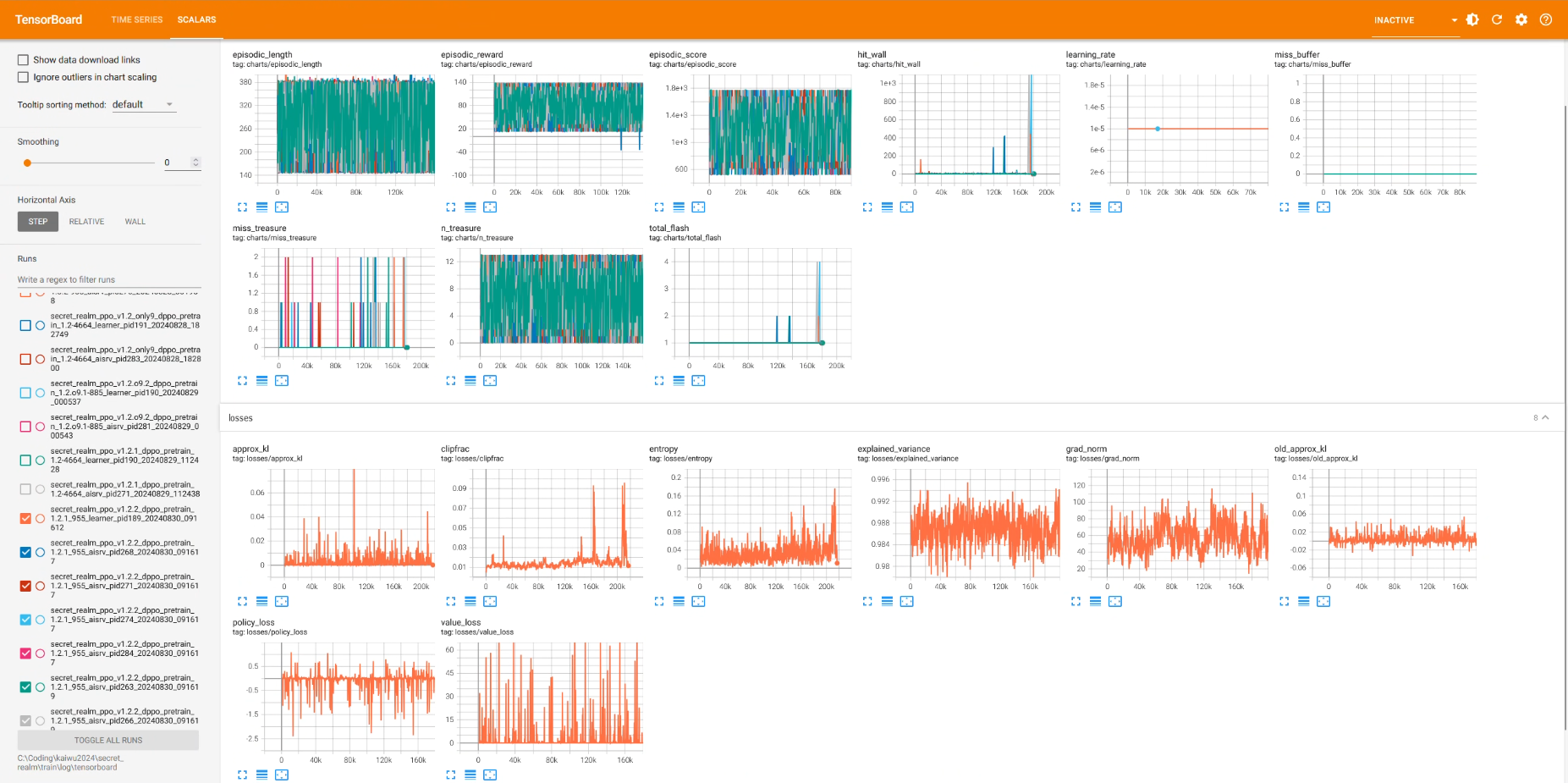
Tensorboard使用方法
由于实在不习惯官方给的记录软件,还是用了传统的Tensorboard,效果图如下
在 agent.py 里面实现了一个下面这个初始化 writer 的init_writer 函数
import os, time
from pathlib import Path
from torch.utils.tensorboard import SummaryWriter
PATH_ROOT = Path(__file__).parents[2]
PATH_LOGS_DIR = PATH_ROOT / "log/tensorboard"
PATH_LOGS_DIR.mkdir(exist_ok=True, parents=True)
def init_writer(agent_type):
# 起个名字
run_name = f"secret_realm_{agent_type}_pid{os.getpid()}_{time.strftime(r'%Y%m%d_%H%M%S')}"
writer = SummaryWriter(str(PATH_LOGS_DIR / run_name))
return writer然后分别在learner和aisrv初始化时候创建它,learner也就是在初始化 Agent时候,aisrv也就是在刚进入train_workflow.py时候(这里不要在Agent中初始化原因是, 所有的aisrv其实公用的同一个Agent实例化结果, 所以他只会被创建一次)
然后就和正常使用tensorboard一样记录就好了, 比如在环境结束时:
if env.done:
logger.info(f"pid={os.getpid()} End episode: gloabl_step={global_step}, episodic_reward={env.total_reward:.2f}, " +
f"episodic_score={int(env.total_score)}, " +
f"miss_treasure={env.miss_treasure}, n_treasure={env.n_treasure}")
writer.add_scalar("charts/episodic_reward", env.total_reward, global_step)
writer.add_scalar("charts/episodic_score", env.total_score, global_step)
writer.add_scalar("charts/episodic_length", env.n_step, global_step)
writer.add_scalar("charts/hit_wall", env.total_hit_wall, global_step)
writer.add_scalar("charts/miss_treasure", env.miss_treasure, global_step)
writer.add_scalar("charts/n_treasure", env.n_treasure, global_step)
writer.add_scalar("charts/total_flash", env.total_flash, global_step)
writer.add_scalar("charts/miss_buffer", env.miss_buffer, global_step)启动方法:
- 如果是从客户端启动训练,直接通过
tensorboard --logdir [你的工作路径]\train\log\tensorboard就可以实时看训练曲线了。 - 如果是从直接运行的
train_test.py那就直接在[你的工作路径]\code\log\tensorboard下打开就行了.
网络结构与特征设计
由于没有使用官方给的dqn,这部分也顺便全部重写了。
我们设计的网络极为简单:纯CNN+拼接+MLP(不能在简单了吧😂),代码为model.py
class Backbone(nn.Module):
def __init__(self):
super().__init__()
self.cnn = nn.Sequential(
nn.Conv2d(4, 32, kernel_size=7, stride=2),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=5, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(4096, 512),
nn.ReLU()
)
self.fc = nn.Sequential(
nn.Linear(512+args.observation_vec_shape[0], 512),
nn.ReLU()
)
self.apply(layer_init)
def forward(self, x):
obs_size = np.prod(args.observation_img_shape)
B = x.shape[0]
img, vec = x[:, :obs_size], x[:, obs_size:]
img = img.view(B, *args.observation_img_shape)
x = torch.cat([self.cnn(img), vec], -1)
return self.fc(x)输入的特征处理函数为definition.observation_process:
feature = np.hstack([
np.stack([ # 图像特征: (4, 51, 51)
obs['obstacle_map'],
obs['memory_map'],
obs['treasure_map'],
obs['end_map'],
], axis=0).reshape(-1),
# 线性特征: (31,)
*obs['norm_pos'],
*obs['treasure_flags'],
*obs['treasure_grid_distance'],
obs['buff_flag'],
obs['buff_pos']['grid_distance'],
obs['end_pos']['grid_distance'],
# 闪现是否可用: (1,)
# 这个mask不是模型的输入,只是一同存储到obs中,需要手动分离出来
obs['legal_act'][1],
]).astype(np.float32)奖励函数设计
这个奖励函数我们大部分是直接沿用了学习期的设计,从definition.py中就能看到我们设计的奖励函数,相应的配置文件位于config.py的Args中:
r = 0
# 1. 重复步骤惩罚,当一个位置重复走过2次以上
ratio = self.total_timestep * args.num_envs / args.total_timesteps
if ratio < 0.5: # 前一半的时候考虑当前位置的惩罚
r -= max(obs['memory_map'][25,25] - args.repeat_step_thre, 0)
# assert obs['memory_map'][25,25] > 0 # won't be > 0
else: # 后一半的时候考虑周围5x5位置的加权惩罚
r -= (args.repeat_punish * np.maximum(
obs['memory_map'][23:28,23:28]-args.repeat_step_thre, 0)).sum()
# 2. 到目标点(这是设计的最大问题,学习别人的奖励函数时,发现可以当宝箱没有收集完时不给这个奖励)
# (这样直接设计奖励,可能让模型丢失部分宝箱)
if terminated:
r += 150
# 对未捡到的宝箱做加权惩罚,加权系数与历史中未捡到该宝箱次数成正比
r -= (obs['treasure_flags'] * self.treasure_reward_coef).sum() * 100
# 对未捡到的buff进行惩罚
r -= obs['buff_flag'] * args.forget_buff_punish
self.treasure_miss_cnt += obs['treasure_flags'].astype(np.int32)
# 移动系数计算,如果是使用闪现则会用更大的系数
dist_reward_coef = args.flash_dist_reward_coef if self.use_flash else args.dist_reward_coef
# 到达终点的相对距离
delta_end_distance = self._obs['end_pos']['grid_distance'] - obs['end_pos']['grid_distance']
r += delta_end_distance * dist_reward_coef
# 3. 到宝箱
if not terminated and score == 100: # 获得宝箱的奖励
r += 100 * (self.treasure_reward_coef * (self._obs['treasure_flags'] ^ obs['treasure_flags'])).sum()
if sum(self._obs['treasure_flags']): # 与最近的宝箱距离
dist_treasure = np.max((self._obs['treasure_grid_distance'] -
self.obs['treasure_grid_distance']
)[self._obs['treasure_flags']])
r += dist_treasure * dist_reward_coef
# 4. 撞墙惩罚
if hit_wall:
r -= args.flash_hit_wall_punish if self.use_flash else args.walk_hit_wall_punish
# 5. buff奖励
if self._obs['buff_flag'] - obs['buff_flag'] == 1:
r += args.get_buff_reward
# 6. 每步的惩罚,如果是初次训练则后半程才加入,如果是接着训练则一直存在
if ratio > 0.5 or args.load_model_id is not None:
r -= args.each_step_punish
# 7. 全局奖励加权系数(由于奖励太大,全部缩小的0.1倍)
r *= args.reward_global_coef我们的版本迭代日志主要为 v0.4.3 -> v1.0 -> v1.1 -> v1.2 -> v1.2.x,最后提交的是v1.2,日志文件可以在code/readme.md中找到。
阶段总结
这次放太多注意力在理解分布式框架和实现PPO算法上了,中间PPO算法实现遇到了很多bug,最后也是没有对奖励再进行微调,没有在所有宝箱位置上对模型进行测试,才导致出现漏掉宝箱的问题,下次要将注意力更多集中在环境调试,网络设计,参数微调,奖励设计上。
这次学习了开悟的分布式框架原理也是一大收获,后面估计我自己也可以照样子设计一个,用于之前毕设未完成的真正强化学习AI训练(当然现在硬件还是不够)。