Flow Matching Generation 原理与Demo
最新更新于: 2026年3月17日晚上9点14分
Flow Matching原理
Flow Matching是一个非常有名的生成模型框架,其他的生成模型还有:VAE、GAN、Diffusion (DDPM)等,Flow Matching优势在于训练效率与生成效率都非常高。本文参考论文1从零开始分析原理,最后给出两个Demo测试该算法。
生成模型要解决什么问题?
对于某个数据集 ,其中 表示样本 的维度,例如
- 1080P的三通道图像维度就是
- 机器人控制就是全部可控制电机的个数
- 从 均匀分布中采样得到的点集
- 从 维正态分布 中采样得到的点集
我们希望得到找到 中数据所满足的分布,称之为真实分布 ,从而能直接从该分布中采样进而生成出新样本 ,达到数据生成的目的
上述的各种生成模型有不同的方法近似得到该策略,Flow Matching给出了一种从噪声分布(标准正态分布)到目标分布的算法,其背后的数学/物理原理非常巧妙很有意思
前置定义
设数据集为 ,数据记为 ,其中 为数据维度, 服从 真实分布,我们希望通过训练的方法近似求出该真实分布
为了解决这个问题,我们直接从直观的思路上来想,是否能每次对噪声分布做微小的移动,从而逐渐移动到真实分布上,下文的“粒子”就是机器学习中的数据,用粒子只是更贴近物理术语好理解些,具体而言:
定义1(概率密度路径, probability density path):与时间 相关的概率密度函数 称为概率密度路径
定义2(流, flow): 为粒子 在时间 下移动到的位置
定义3(时变向量场, time-dependent vector field, VF): 为 时刻下粒子 的移动方向
不难发现,流就是一个粒子空间位置,时变向量场就是粒子速度,二者满足如下关系(微分和积分关系)
数学上称之为微分同胚(diffeomorphic)该映射具有连续可微的性质,换句话说就是一一对应
我们还可以发现流 描述了每个粒子在每个时刻下的位置,因此对于 时刻下粒子的出现概率 ,给出 和 ,则不难得到 ,数学上称该算子 为前推算子,具体表达式见论文中Eq.4
我们可以固定一个初始随机分布 (标准正态分布) 通过某个流 到达最后的 ,因此问题转化为找到 ,而流和时变向量场又是一一对应关系,求解 变为我们的终极问题
定义4(Flow Matching, FM):对于神经网络参数化的函数 我们期望最小化目标
其中 均匀分布,,该目标称为Flow Matching目标。
P.S. 这个目标其实是向量场的近似,但却被称为流匹配,可能是求解流是最终目标,而向量场则是求解其的等价替代品
本论文提出关键核心就是将FM转为可求解的条件流匹配(Condition FM),下面详细介绍
Condition Flow Matching两个核心定理
直接求解 没有头绪,但是将其通过条件分布边缘化(积分)是否可以得到呢,于是引出如下定理
定理1(边缘化条件概率路径)
设 ,条件概率路径 由条件向量场 得到,对于真实分布 ,向量场可通过边缘化得到
证明:我们利用到两个重要公式
连续性方程为流体力学中的重要公式,描述了场(流速) 和概率路径(流体密度) 的关系, 为概率通量(质量流量,流过单位截面的概率质量),该公式表示局部密度变化等于流入和流出该区域的通量差
因此在常见正则性假设下,可取
两边同除 即得结论
QED
定理2(FM与CFM关于网络参数具有相同梯度)
为真实分布, 为真实数据,则条件流匹配(Condition Flow Matching, CFM)最小化目标为
式(1)与(2)关系为 ,即关于 的导数相同,梯度下降法求解 二者等价
证明:
由于 ,则
由于最后关于 求导,仅考虑包含 的项,即前两项,只需分别证明期望意义下相等:
第一项
第二项
综上:,则
QED
如何训练?
我们证明了最重要的定理条件流匹配定理2,如何使用它来训练呢?随机采样数据集中的一个样本 ,虽然目标向量场 很难获得,但是条件向量场 确实可以直接构造得到的,这个构造只需找到两个边界条件做线性插值即可,论文中将其称之为最优传输插值(Optimal Transport (OT) interpolant),因为我们可以观察两个特殊时间点的分布:
- 时,(标准正态分布)
- 时,(一个均值为 、协方差为 且 的正态分布)
于是容易通过线性插值构造出OT路径,也称条件流(Conditional flow)
由于流和场就是微分关系,因此条件向量场就是
其中 ,由式(3)可知 ,带入式(4)可得
将 和式(4)带入CFM损失函数 式(2)中,可以得到我们训练神经网络的最小化目标
具体训练中,训练集随机选择batch集合,其中样本为 ,从均匀分布中采样时间 ,带入 中,计算梯度即可
的网络选择可以是:MLP(简单的拟合),UNet+ResNet(图像生成),Transformer(复杂的拟合,机器人控制,如OmniXtreme)
如何推理?
我们的目标式通过 ,中间的过程是通过每个时刻 下的 给出,所以最简单的方法就是固定时刻步进长度 ,然后每次步进这个长度的距离即可,这个方法也称为Euler法:
这就是ODE求解器,也是求解数值积分面积的方法,但是Euler法还是太过于暴力且不精准,论文中使用的是Dormand-Prince method(dopri5,多尔曼-普林斯5阶近似方法),也就是对Runge-Kutta method(RK4, 龙格-库塔4阶近似方法)的改进,能自动调整 的大小,在梯度较小式增大 ,从而加快生成速度,且精确比Euler法更高
例子
下面这些例子中我们就用简单的欧拉法,均匀设定步长,当推进次数为 时,步长为 ,来体现不同步长时候生成的结果
依赖安装包pytorch,matplotlib,任意版本python,最好别低于3.8
代码均为Gemini 3.1 Pro生成,经过调试得到,训练显卡为RTX 4080
二维棋盘图分布
设 ,我们的目标分布是 上长度为 均匀分布的正方形棋盘,下左图所示
| 目标分布 | 生成分布 |
|---|---|
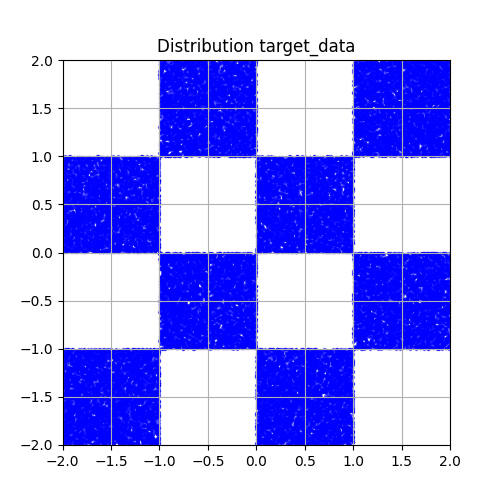 |
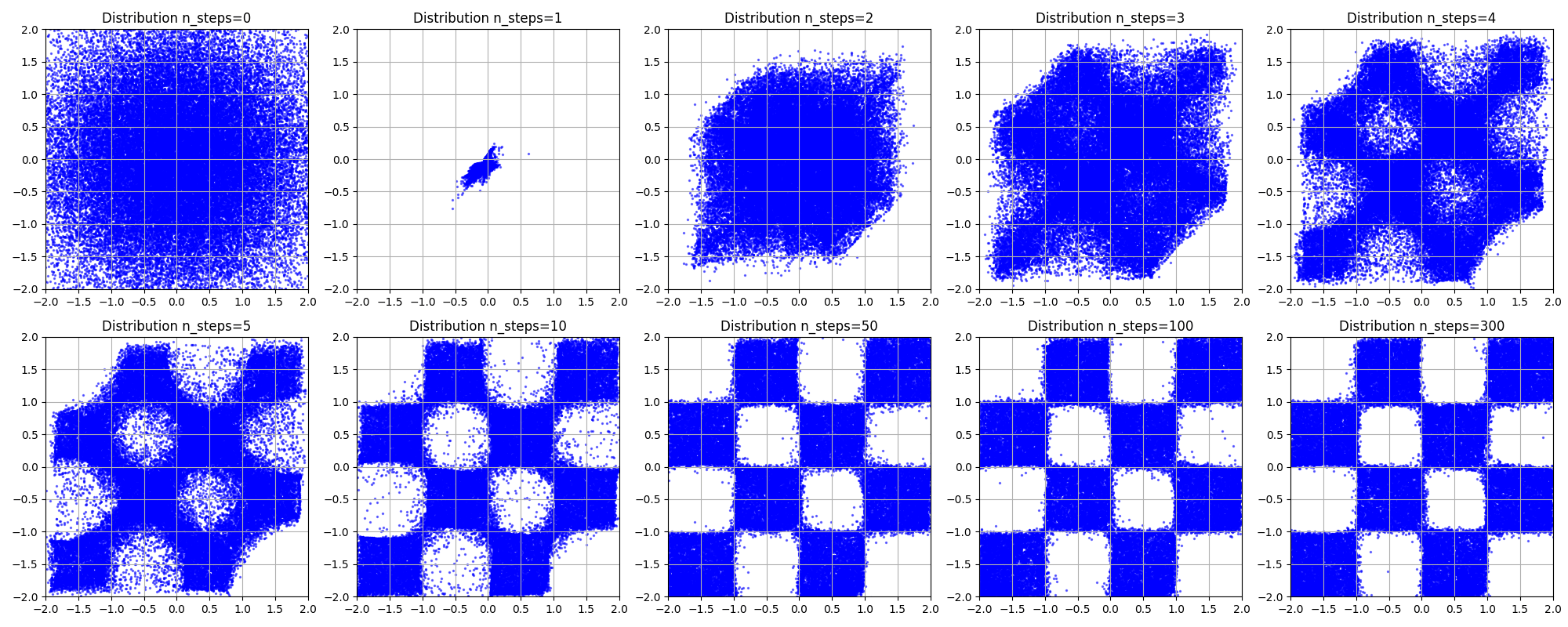 |
网络使用的是5层512神经元的MLP,训练50秒得到,完整代码如下
import time
import torch
import torch.nn as nn
from tqdm import tqdm
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class MinimalVectorFieldNet(nn.Module):
def __init__(self, dim=2):
super().__init__()
hidden_dim = 512
# 网络输入维度是 dim + 1 (空间维度 + 时间维度 t)
self.net = nn.Sequential(
nn.Linear(dim + 1, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, dim) # 输出维度与 x 一致,代表各维度的移动速度
)
def forward(self, x, t):
# 确保时间 t 的 shape 正确,并与空间特征拼接
t_expand = t.view(-1, 1).expand(-1, 1) if t.dim() == 1 else t
xt = torch.cat([x, t_expand], dim=-1)
return self.net(xt)
def train_step(model, optimizer, x1, sigma_min=1e-5):
"""
x1: 真实的批量数据 (比如你从 DataLoader 里抽出来的真实猫狗图)
"""
batch_size = x1.shape[0]
# a. 采样起点:抽取纯高斯白噪声 x0
x0 = torch.randn_like(x1)
# b. 随机抽取连续时间:从 U[0, 1] 均匀分布采样 t [cite: 41, 59]
t = torch.rand(batch_size, 1, device=x1.device)
# c. 根据 OT 直线方程,计算粒子在时刻 t 的精确位置 x_t (论文 Eq. 22)
# ψ_t(x0) = (1 - (1 - sigma_min)*t)*x0 + t*x1
xt = (1 - (1 - sigma_min) * t) * x0 + t * x1
# d. 论文的工程魔法:回归目标 (论文 Eq. 23)
# 注意!论文里代换完后,目标速度不再依赖 t 作分母,直接变成了常数速度!
target_u = x1 - (1 - sigma_min) * x0
# e. 让神经网络预测当前位置 xt 应该往哪流
pred_v = model(xt, t)
# f. 极其朴素的均方误差 (MSE) 损失
loss = torch.mean((pred_v - target_u) ** 2)
# 反向传播更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
def generate_euler(model, num_steps=20, dim=2, num_samples=1, ax=None):
"""
因为 OT 路径极其平滑且接近直线,即便不使用复杂的龙格-库塔 dopri5,
直接用欧拉法且步数(NFE)设得很小,也能得到不错的结果 [cite: 153, 154]。
"""
model.eval()
with torch.no_grad():
# 起点:随机纯噪声
x = torch.randn(num_samples, dim).to(device)
# 确定固定的步长 dt
dt = 1.0 / (num_steps + 1e-9)
t = torch.tensor([0.0]).repeat(num_samples, 1).to(device) # 从 t=0 开始
bar = tqdm(range(num_steps), desc="Generating Samples")
for _ in bar:
# 1. 问神经网络:我现在在 x,时间是 t,该往哪走?速度是多少?
v = model(x, t)
# 2. 闭着眼睛往前莽一个 dt 的距离 (Euler step)
x = x + v * dt
# 3. 时间流逝
t = t + dt
display_data(x, fname=f"n_steps={num_steps}.png", ax=ax)
# 最终到达 t=1,此时的 x 就是生成的样本!
return x
def generate_checkerboard_data(n_samples=10000):
"""
生成一个二维的马赛克/棋盘格数据。
为了与标准正态分布的噪声先验更好地匹配,我们让数据分布在 [-2, 2] 左右。
"""
# 1. 在一个较大的范围内均匀撒点 (这里取 [-2, 2])
x1 = torch.rand(n_samples * 4, 2) * 4 - 2
x1 = x1.to(device)
# 2. 判断点属于哪个方块区域 (向下取整)
x_int = torch.floor(x1[:, 0])
y_int = torch.floor(x1[:, 1])
# 3. 利用奇偶性的“异或”逻辑,只保留间隔的方块(形成马赛克)
mask = (x_int % 2) == (y_int % 2)
data = x1[mask]
# 取所需数量的样本
data = data[:n_samples]
# # 可选:给点加一点点极小的微小噪声,防止数据绝对离散化(流模型更喜欢连续空间)
# data += torch.randn_like(data) * 0.05
return data
def display_data(target_data, fname="data.png", ax=None):
use_ax = ax is not None
if ax is None:
plt.figure(figsize=(5, 5))
ax = plt.gca()
td = target_data.cpu().numpy()
ax.scatter(td[:, 0], td[:, 1], s=2, alpha=0.5, color='blue')
ax.set_title(f"Distribution {fname.split('.')[0]}")
ax.set_xlim(-2, 2)
ax.set_ylim(-2, 2)
ax.grid(True)
if not use_ax:
plt.tight_layout()
print("HI")
plt.savefig(fname, dpi=100)
plt.close()
def train():
bar = tqdm(range(num_epochs), desc="Training")
# --- 训练模型 ---
for epoch in bar:
random_indices = torch.randperm(target_data.size(0))
mean_loss = 0.0
for i in range(0, target_data.size(0), batch_size):
batch_indices = random_indices[i:i+batch_size]
x1_batch = target_data[batch_indices]
loss = train_step(model, optimizer, x1_batch)
mean_loss += loss * x1_batch.size(0)
mean_loss /= target_data.size(0)
# if (epoch + 1) % 10 == 0:
bar.set_postfix({"Loss": f"{mean_loss:.4f}"})
epoches.append(epoch + 1)
losses.append(mean_loss)
name = f"net_{int(time.strftime('%Y%m%d_%H%M%S'))}.pth"
static_dict = {f"{k}": v.detach().cpu() for k, v in model.state_dict().items()}
torch.save(static_dict, name)
plt.plot(epoches, losses, marker='o')
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.savefig("training_loss.png", dpi=100)
plt.close()
return name
# --- 测试数据长什么样 ---
if __name__ == "__main__":
num_epochs = 500
num_smaples = int(5e4)
target_data = generate_checkerboard_data(num_smaples)
display_data(target_data, fname="target_data.png")
model = MinimalVectorFieldNet(dim=2).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
batch_size = 512
epoches, losses = [], []
model_name = train()
# --- 生成样本 ---
# model.load_state_dict(torch.load("checkerboard/net_20260315162833.pth", map_location=device, weights_only=True)) # 替换成你训练好的模型文件名
model.load_state_dict(torch.load(model_name, map_location=device, weights_only=True)) # 替换成你训练好的模型文件名
num_steps_list = [0,1,2,3,4,5,10,50,100,300]
fig, axs = plt.subplots(2, 5, figsize=(20, 8))
for num_steps in num_steps_list:
i, j = divmod(num_steps_list.index(num_steps), 5)
generate_euler(model, num_steps=num_steps, num_samples=num_smaples, ax=axs[i][j])
plt.tight_layout()
plt.savefig("generated_samples.png", dpi=100)
plt.close()
MNIST手写数字生成
训练这个最好先确定PyTorch有显卡加速不然太慢,训练用时21分钟,网络使用UNet+ResNet,生成效果如下
| step0 | step1 | step2 | step3 | step4 |
|---|---|---|---|---|
 |
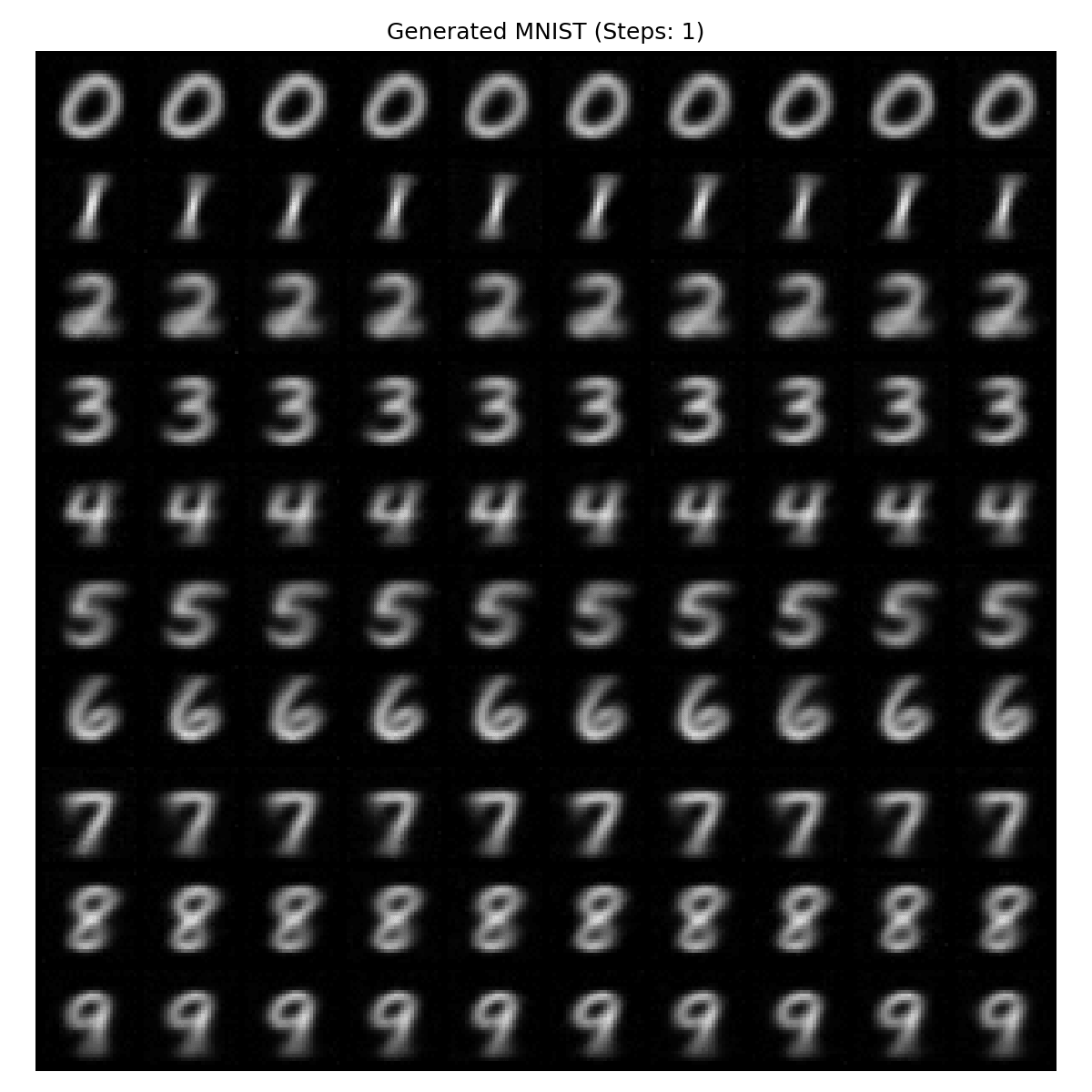 |
 |
 |
 |
| step10 | step100 | step300 | step1000 |
|---|---|---|---|
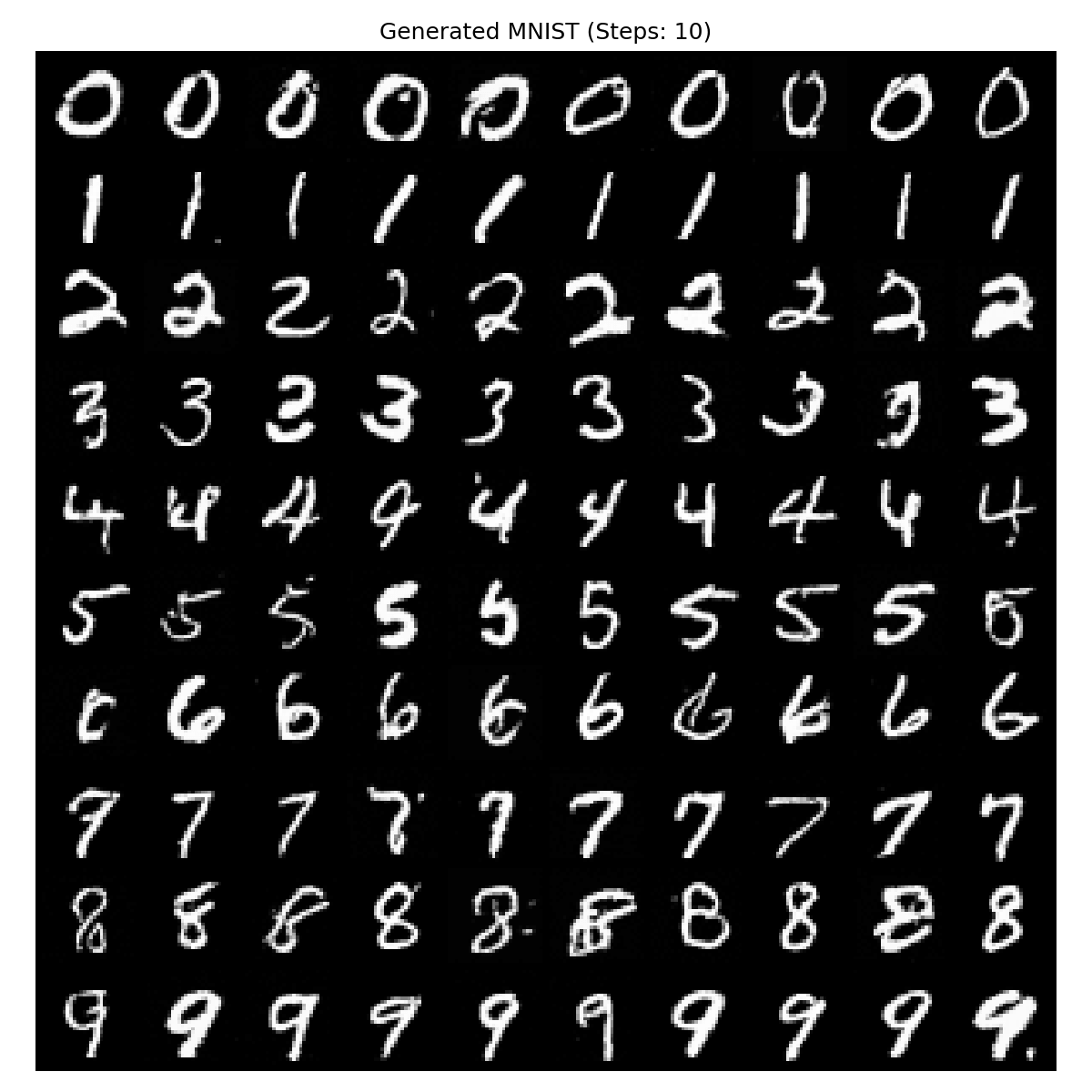 |
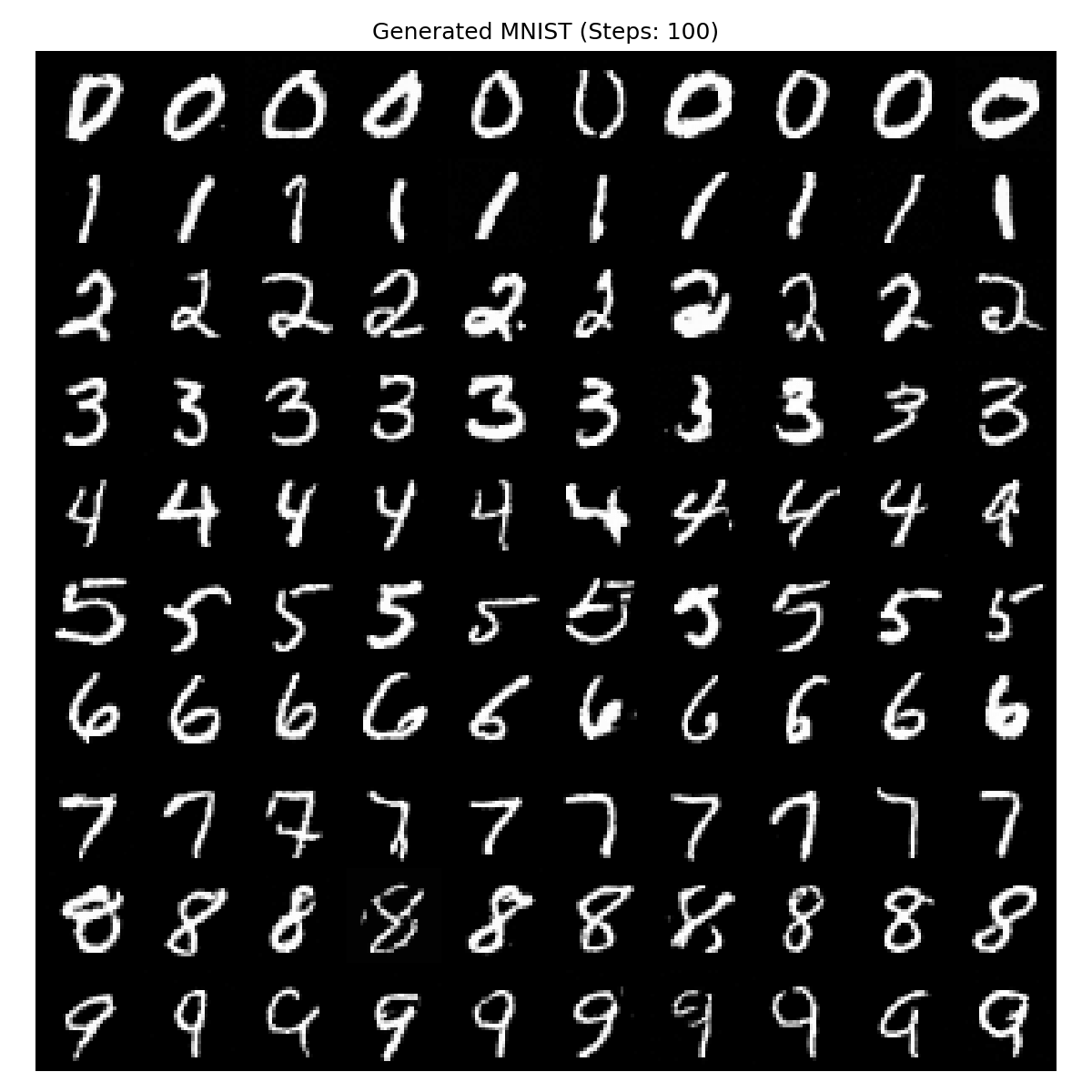 |
 |
 |
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.utils import make_grid
from tqdm import tqdm
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class ResBlock(nn.Module):
"""标准的残差块,带有 GroupNorm,对图像生成极其重要"""
def __init__(self, in_ch, out_ch, time_emb_dim):
super().__init__()
self.conv1 = nn.Sequential(
nn.GroupNorm(8, in_ch), # 使用 GroupNorm 稳定特征
nn.SiLU(),
nn.Conv2d(in_ch, out_ch, 3, padding=1)
)
# 将时间特征投影到这个层的通道数
self.time_proj = nn.Sequential(
nn.SiLU(),
nn.Linear(time_emb_dim, out_ch)
)
self.conv2 = nn.Sequential(
nn.GroupNorm(8, out_ch),
nn.SiLU(),
nn.Conv2d(out_ch, out_ch, 3, padding=1)
)
# 如果输入输出通道不同,需要一个 1x1 卷积对齐残差
self.shortcut = nn.Conv2d(in_ch, out_ch, 1) if in_ch != out_ch else nn.Identity()
def forward(self, x, t_emb):
h = self.conv1(x)
# 将投影后的时间特征加到特征图上
h = h + self.time_proj(t_emb)[..., None, None]
h = self.conv2(h)
return h + self.shortcut(x)
class UNet(nn.Module):
def __init__(self, in_channels=1, num_classes=10):
super().__init__()
time_dim = 128
# 时间嵌入
self.time_embed = nn.Sequential(
nn.Linear(1, time_dim),
nn.SiLU(),
nn.Linear(time_dim, time_dim)
)
# 标签嵌入
self.label_embed = nn.Sequential(
nn.Linear(num_classes, time_dim),
nn.SiLU(),
nn.Linear(time_dim, time_dim)
)
# 输入投影 (1 -> 32)
self.init_conv = nn.Conv2d(in_channels, 32, 3, padding=1)
# 下采样模块 (加入了 ResBlock)
self.down1 = ResBlock(32, 64, time_dim)
self.pool1 = nn.MaxPool2d(2) # 28 -> 14
self.down2 = ResBlock(64, 128, time_dim)
self.pool2 = nn.MaxPool2d(2) # 14 -> 7
# 瓶颈层
self.bot1 = ResBlock(128, 128, time_dim)
self.bot2 = ResBlock(128, 128, time_dim)
# 上采样模块 (拼接 Skip Connection 后,通道数翻倍)
self.up1 = nn.Upsample(scale_factor=2, mode='nearest')
self.up_res1 = ResBlock(128 + 128, 64, time_dim) # 7 -> 14
self.up2 = nn.Upsample(scale_factor=2, mode='nearest')
self.up_res2 = ResBlock(64 + 64, 32, time_dim) # 14 -> 28
# 输出投影 (32 -> 1)
self.out = nn.Sequential(
nn.GroupNorm(8, 32),
nn.SiLU(),
nn.Conv2d(32, in_channels, 3, padding=1)
)
def forward(self, x, t, y=None):
t_expand = t.view(-1, 1)
emb = self.time_embed(t_expand)
if y is not None:
emb = emb + self.label_embed(y)
# 注意:现在 ResBlock 会自己处理 emb 的空间维度扩展,所以不需要 [..., None, None] 了
x0 = self.init_conv(x)
d1 = self.down1(x0, emb)
p1 = self.pool1(d1)
d2 = self.down2(p1, emb)
p2 = self.pool2(d2)
b = self.bot1(p2, emb)
b = self.bot2(b, emb)
u1 = self.up1(b)
c1 = torch.cat([u1, d2], dim=1) # 拼接
u1 = self.up_res1(c1, emb)
u2 = self.up2(u1)
c2 = torch.cat([u2, d1], dim=1) # 拼接
u2 = self.up_res2(c2, emb)
return self.out(u2)
def train_step(model, optimizer, x1, y1, sigma_min=1e-5):
batch_size = x1.shape[0]
x0 = torch.randn_like(x1)
t = torch.rand(batch_size, 1, device=x1.device)
t_math = t.view(batch_size, 1, 1, 1)
xt = (1 - (1 - sigma_min) * t_math) * x0 + t_math * x1
target_u = x1 - (1 - sigma_min) * x0
# === 修改:前向传播时传入标签 y1 ===
pred_v = model(xt, t, y1)
loss = torch.mean((pred_v - target_u) ** 2)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
# 推理生成
def generate_euler(model, num_steps=20, num_samples=100):
model.eval()
with torch.no_grad():
x = torch.randn(num_samples, 1, 28, 28).to(device)
dt = 1.0 / (num_steps + 1e-9)
t = torch.tensor([0.0]).repeat(num_samples, 1).to(device)
# === 新增:生成我们想要的标签 (0到9,每个数字重复10次) ===
# 这样生成的图片就会是完美的 10x10 矩阵,第一行全是0,第二行全是1...
labels = torch.arange(10).repeat_interleave(10).to(device)
y_onehot = F.one_hot(labels, num_classes=10).float()
bar = tqdm(range(num_steps), desc=f"Generating {num_steps} Steps")
for _ in bar:
# === 传入指定条件的 y_onehot ===
v = model(x, t, y_onehot)
x = x + v * dt
t = t + dt
# 注意把这里改为 nrow=10 配合我们的数据排列
display_images(x, fname=f"mnist_cond_gen_{num_steps}_steps.png", nrow=10, nstep=num_steps)
return x
# 记得把 display_images 的参数加上 nrow=10
def display_images(images, fname="images.png", nrow=8, nstep=0):
images = (images + 1) / 2.0
images = torch.clamp(images, 0, 1)
grid = make_grid(images, nrow=nrow)
plt.figure(figsize=(8, 8))
# PyTorch 的图片通道在前面,matplotlib 需要通道在后面,所以用 permute 调换
plt.imshow(grid.permute(1, 2, 0).cpu().numpy(), cmap='gray')
plt.title(f"Generated MNIST (Steps: {nstep})")
plt.axis('off')
plt.tight_layout()
plt.savefig(fname, dpi=150)
plt.close()
def train(model, optimizer, dataloader, num_epochs):
bar = tqdm(range(num_epochs), desc="Training")
epoches, losses = [], []
for epoch in bar:
mean_loss = 0.0
# 3. 数据集迭代:直接从 DataLoader 取真实的图片
for images, labels in dataloader:
x1_batch = images.to(device)
# === 新增:把数字标量转成 10维 One-Hot 向量 ===
y1_batch = F.one_hot(labels, num_classes=10).float().to(device)
# 传入 y1_batch
loss = train_step(model, optimizer, x1_batch, y1_batch)
mean_loss += loss * x1_batch.size(0)
mean_loss /= len(dataloader.dataset)
bar.set_postfix({"Loss": f"{mean_loss:.4f}"})
epoches.append(epoch + 1)
losses.append(mean_loss)
name = f"mnist_fm_net_{int(time.strftime('%Y%m%d_%H%M%S'))}.pth"
torch.save(model.state_dict(), name)
plt.plot(epoches, losses, marker='o')
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("MNIST Training Loss")
plt.savefig("mnist_training_loss.png", dpi=100)
plt.close()
return name
if __name__ == "__main__":
# 配置参数
num_epochs = 100 # MNIST比较简单,50个Epoch就能出像样的结果
batch_size = 512
dim = 28 * 28 # 784
# 4. 下载并预处理 MNIST 数据集
transform = transforms.Compose([
transforms.ToTensor(), # 把像素变到 [0, 1]
transforms.Normalize((0.5,), (0.5,)) # 把 [0, 1] 平移缩放到了我们需要的 [-1, 1]
])
# 会自动在当前目录下建一个 'data' 文件夹下载数据
dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)
# 初始化网络和优化器
model = UNet(in_channels=1).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4)
# 训练模型
print("Starting Training on MNIST...")
model_name = train(model, optimizer, dataloader, num_epochs)
# 加载刚训练好的模型
# model.load_state_dict(torch.load("mnist/mnist_fm_net_20260315180058.pth", map_location=device, weights_only=True))
model.load_state_dict(torch.load(model_name, map_location=device, weights_only=True))
# 采样生成 64 张图片 (拼成 8x8 的图)
print("Generating Samples...")
for num_steps in list(range(0, 11)) + [10, 20, 50, 100, 150, 200, 300, 500, 1000]:
generate_euler(model, num_steps=num_steps, num_samples=100)
print("Done! Check your current directory for the generated images.")