2025开悟比赛初赛
最新更新于: 2025年8月9日下午2点52分
这里记录一下本次初赛的训练记录以及相对去年的一些改动, 分布式逻辑介绍放在去年的blog中2024开悟智能体比赛(海选赛), 开源代码继续放在kaiwu_taichu的2025分支中.
题目变化
今年同时报名了两个赛道: 王者高级赛道, 具身赛道, 两个赛道的初赛除了地图不一样外, 还有以下一些不同.
相比去年8个固定位置的随机宝箱,视野范围51x51,今年难度明显提升,将8个宝箱、buff、起点、终点位置全部随机产生,并存在随机一个位置的障碍物封路,而智能体高级赛道和具身赛道的obs还并不一样:
- 具身视野范围51x51, 王者视野范围11x11
- 具身完全看不到视野外的宝箱、终点、buff位置,王者可以看到视野外宝箱、终点、buff的大致位置(这里的大致位置指的是将360度划分为8个方向,每个方向按照距离单位20进行离散,给出每个物件的大致位置)
特征工程
我们尝试复刻去年的状态输入,分为4个维度的51x51图像输入 (王者赛道代码MapManager.get_around_feature:
- 第一维: 障碍物信息, -1未知(仅在王者赛道中存在), 0障碍物, 1通路
- 第二维: 记忆信息, 即之前走过的格子次数, 并限制在
- 第三维: 宝箱, buff, 宝箱为0.5, 1.0, buff为-0.5, -1.0, 分别表示大致位置和准确位置
- 第四维: 终点, 0.5, 1.0分别表示大致位置和准确位置
由于王者的视野范围只有11x11, 而且有大致位置的物件, 因此需要对视野外的物件限制相对位置到以英雄为中心的51x51图像内, 如下图所示
| 第1帧地图 | 第1帧周围信息地图 | 第199帧地图 | 第199帧周围信息地图 |
|---|---|---|---|
 |
 |
 |
 |
上图中的颜色分别表示:
- 蓝色: 英雄
- 绿色: 宝箱
- 红色: Buff
- 粉色: 终点
- 灰色: 未知位置
- 白色: 通路
- 黑色: 障碍物
- 通路上的灰色: 记忆路径 (走过的轨迹)
该图可以通过
StateManager保存得到, 参考demos/README.md
算法设计
本次官方给出了PPO实现, 但是最开始在上面测试了很久, 训练效果并不理想, 可能是sample_production_and_consumption_ratio过高导致的, 我们测试了dqn还是ppo, 都必须将该值保持在10以下, 并且越低越好, 后面的1v1比赛可能需要在2以下更好, 通过调整learner_train_sleep_seconds训练休息时间来调整
最后用的是ddqn, 还保存了默认的target_dqn, 使用只需将文件名重命名为algorithm.py即可
网络设计
最开始用的是纯CNN的网络设计 model_cnn.py:
self.q_cnn = nn.Sequential(
nn.Conv2d(4, 32, kernel_size=7, stride=2),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=5, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
MLP([4096, 512], "q_cnn", non_linearity_last=True)
)
self.mlp = nn.Sequential(
MLP([512 + Config.HERO_FEATURE_DIM, 256], "mlp", non_linearity_last=True),
MLP([256, action_shape], "mlp")
)更新后的网络在全连接部分加入了simbaV2的权重限制和网络架构修改, 代码为model.py
奖励设计
完整奖励包含如下几项:
- 到终点奖励
- 惩罚没有获得的宝箱
- 闪现距离惩罚 (官方写闪现距离为16个单位, 当距离小于15时进行惩罚)
- 撞墙惩罚
- 宝箱奖励
- buff奖励
- 步数惩罚
- 距离奖励
- 周围重复步数惩罚
- 探索奖励 (具身才用)
奖励函数位于StateManager.get_reward(), 配置系数位于conf/conf.py最下面一部分
# 1. 到终点
if self.terminated:
# 终点奖励
r += cfg.REW_FINISH
if self.truncated:
r -= cfg.REW_TRUNCATED_PUNISH
# 2. 惩罚没有得到的宝箱
if self.terminated or self.truncated:
rew_miss_treasures = 0
for treasure in self.treasures:
if treasure.pos[0] != -1 and treasure.available: # 遗漏的宝箱
rew_miss_treasures -= cfg.REW_TREASURE
# r += rew_miss_treasures * self.win_rate # 胜率越高, 惩罚比例越大
r += rew_miss_treasures
# 3. 闪现距离惩罚(官方写闪现距离为16个单位)
use_flash = self.last_action >= 8
if use_flash:
r += np.clip(
(delta_distance - 15) * cfg.REW_FLASH,
-5.0, 0.0, dtype=np.float32
)
# 4. 撞墙惩罚
if hit_wall:
r -= cfg.REW_HIT_WALL_PUNISH
# 5. 宝箱奖励
treasure_get = (self.curr_frame['obs']['score_info']['treasure_collected_count'] -
last_frame['obs']['score_info']['treasure_collected_count'])
if treasure_get > 0:
r += cfg.REW_TREASURE * treasure_get
# 6. buff奖励
if (
self.curr_frame['obs']['score_info']['buff_count'] -
last_frame['obs']['score_info']['buff_count'] > 0
):
r += cfg.REW_BUFF * (0.5 ** self.buff_count) # 每次buff奖励递减
self.buff_count += 1
# 7. 步数惩罚
r -= cfg.REW_EACH_STEP_PUNISH
# 8. 距离奖励
# 优先宝箱
min_distance, treasure_delta_distance = None, None
for treasure in self.treasures:
if treasure.pos[0] != -1 and treasure.available: # 遗漏的宝箱
if min_distance is None or treasure.real_distance < min_distance: # 最近的宝箱
min_distance = treasure.real_distance
treasure_delta_distance = treasure.last_real_distance - treasure.real_distance
if not treasure.found: # 当没找到时, 则给出限制后的距离 (-1, 1)
treasure_delta_distance = np.clip(treasure_delta_distance, -1.0, 1.0, dtype=np.float32)
if treasure_delta_distance is not None: # 如果有宝箱只考虑最近宝箱距离
r += treasure_delta_distance * cfg.REW_DISTANCE
if self.end.pos[0] != -1: # 终点存在
d = self.end.last_real_distance - self.end.real_distance
if not self.end.found: # 当没找到时, 则给出限制后的距离 (-1, 1)
d = np.clip(d, -1.0, 1.0, dtype=np.float32)
r += d * cfg.REW_DISTANCE
# 9. 周围重复步数惩罚
around_memory = self.map_manager.get_around_memory(cfg.REW_MEMORY_PUNISH_SIZE)
r -= min(
max(np.sum(around_memory) - cfg.REW_MEMORY_PUNISH_THRESHOLD, 0.0) * cfg.REW_MEMORY_PUNISH_COEF,
1.0
)
# 10. 探索奖励
r += self.map_manager.now_explore_grid * cfg.REW_EXPLORATION#################### 奖励 ####################
REW_FINISH = 15 # 到终点奖励
REW_TRUNCATED_PUNISH = 80 # 截断惩罚
REW_TREASURE = 10 # 获得宝箱奖励, 到终点但错失的宝箱就是惩罚
REW_FLASH = 0.1 # 闪现距离减15乘系数并对奖励做clip(-5, 0)范围
REW_DISTANCE = 0.1 # 距离奖励向目标 (终点) 移动 (每一帧进行一次奖励)
REW_HIT_WALL_PUNISH = 0.1 # 撞墙惩罚 (每一帧进行一次惩罚)
REW_BUFF = 0.5 # 获得buff奖励
REW_EACH_STEP_PUNISH = 0.02 # 每步的惩罚
REW_MEMORY_PUNISH_SIZE = 3 # 周围重复步数惩罚的大小
REW_MEMORY_PUNISH_THRESHOLD = 9 # 周围重复步数惩罚的阈值
REW_MEMORY_PUNISH_COEF = 0.1 # 周围重复步数惩罚系数
REW_EXPLORATION = 0.000 # 探索奖励 (王者无需探索奖励)
REW_GLOBAL_SCALE = 1.0 # 奖励缩放系数在v1.2版本中尝试对惩罚没有获得的宝箱乘上实时的胜率win_rate来促进前期到达终点, 也导致了模型在后期无法捡到所有宝箱, 在v1.3中删除
训练曲线
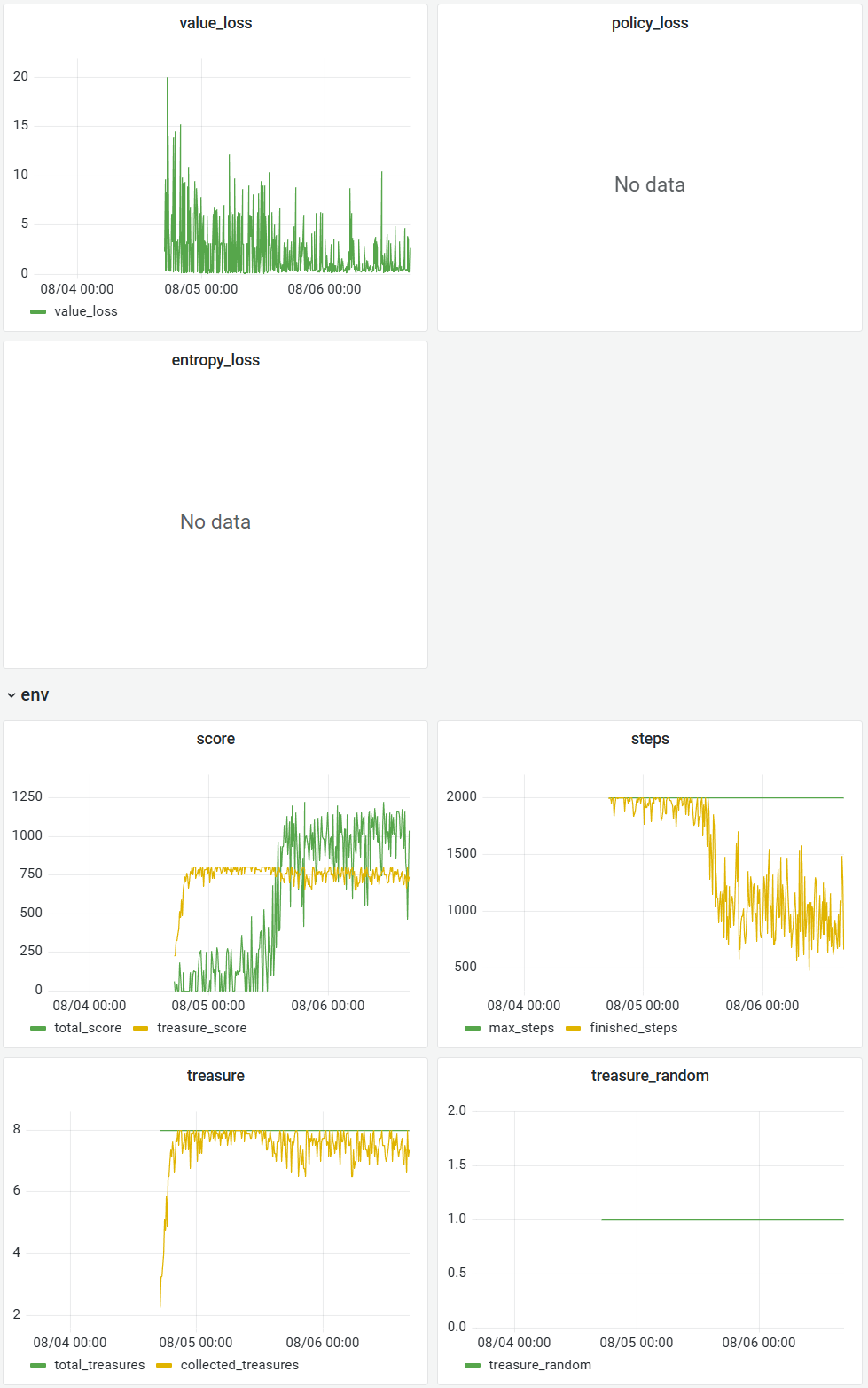
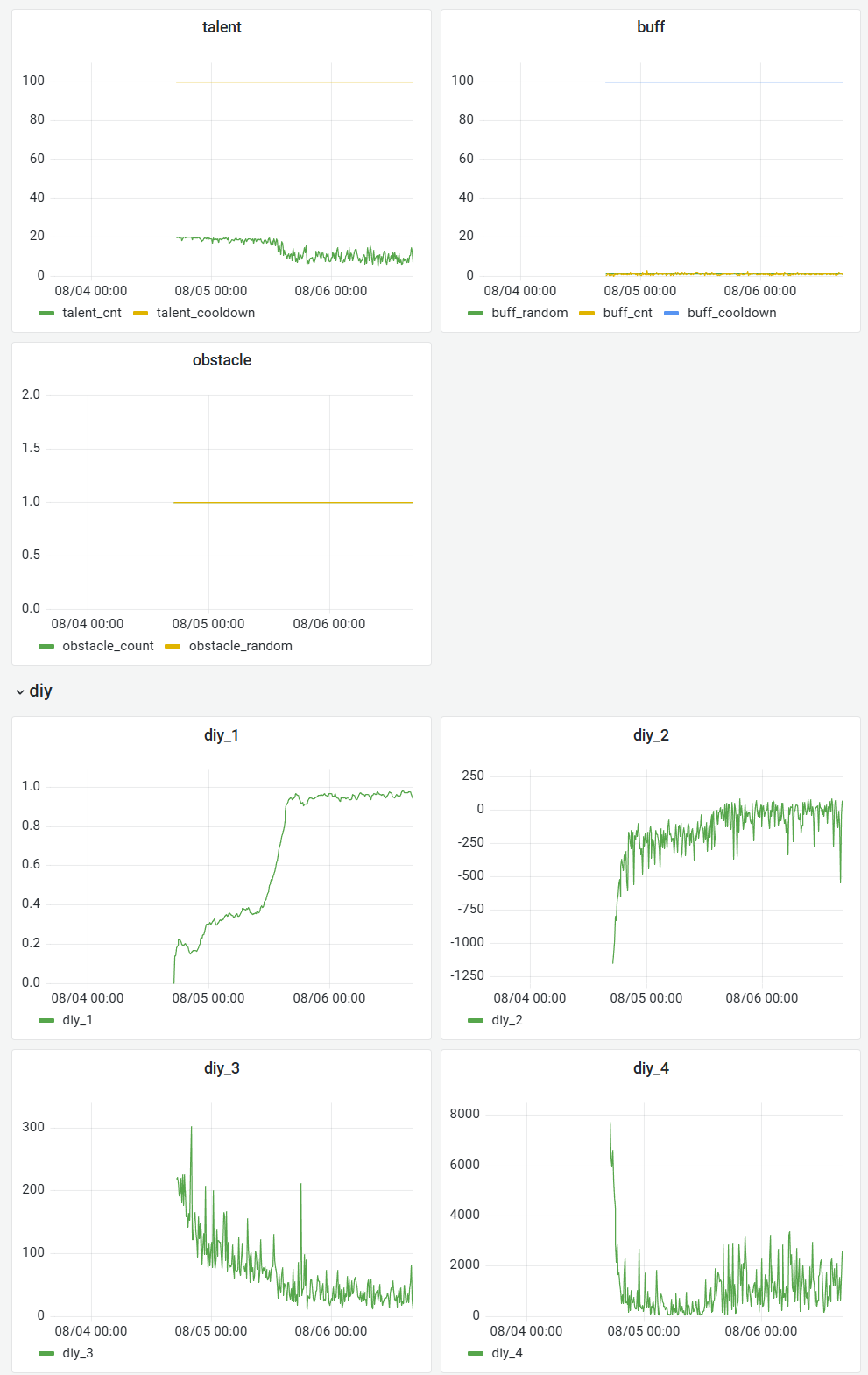
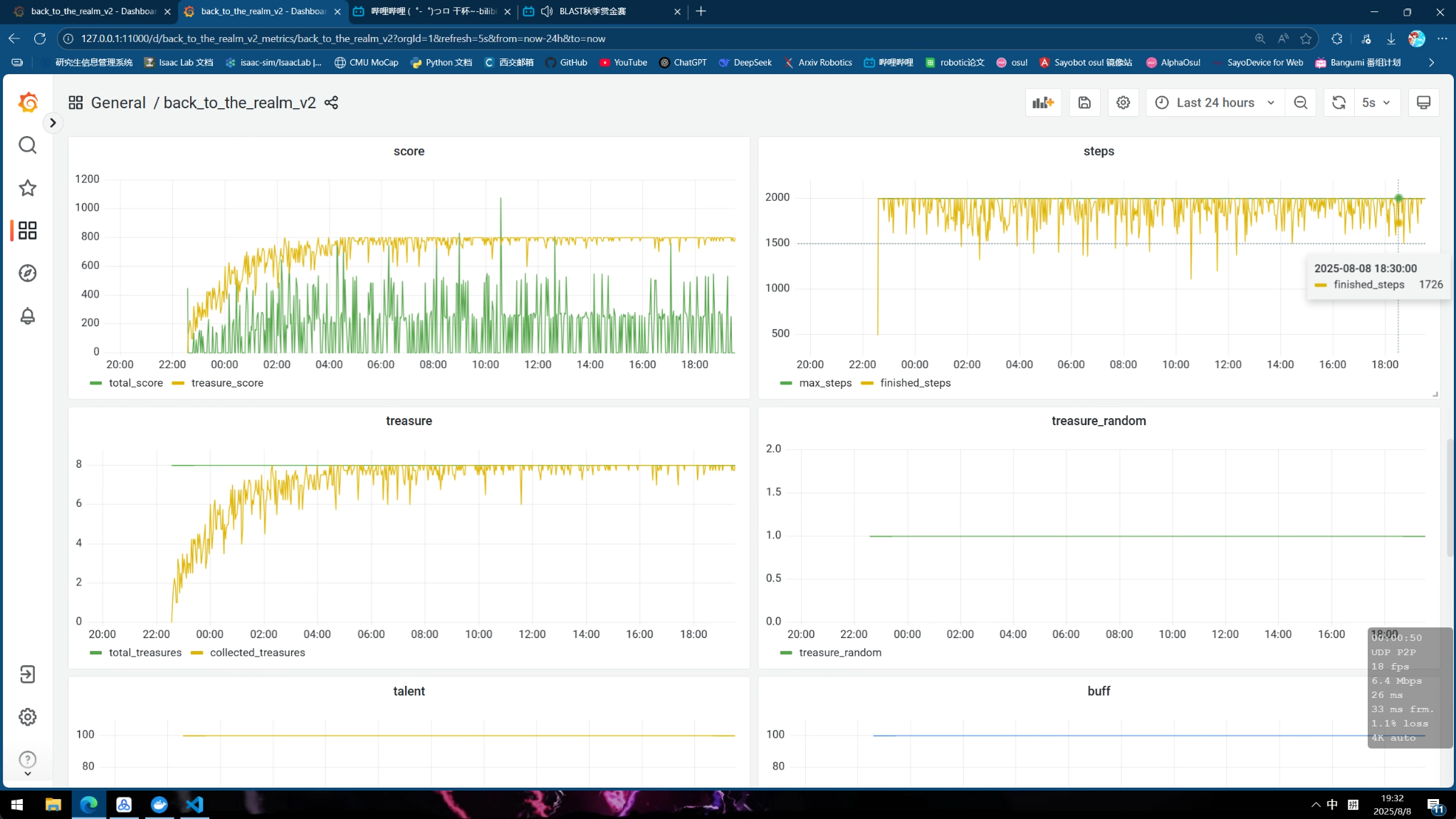
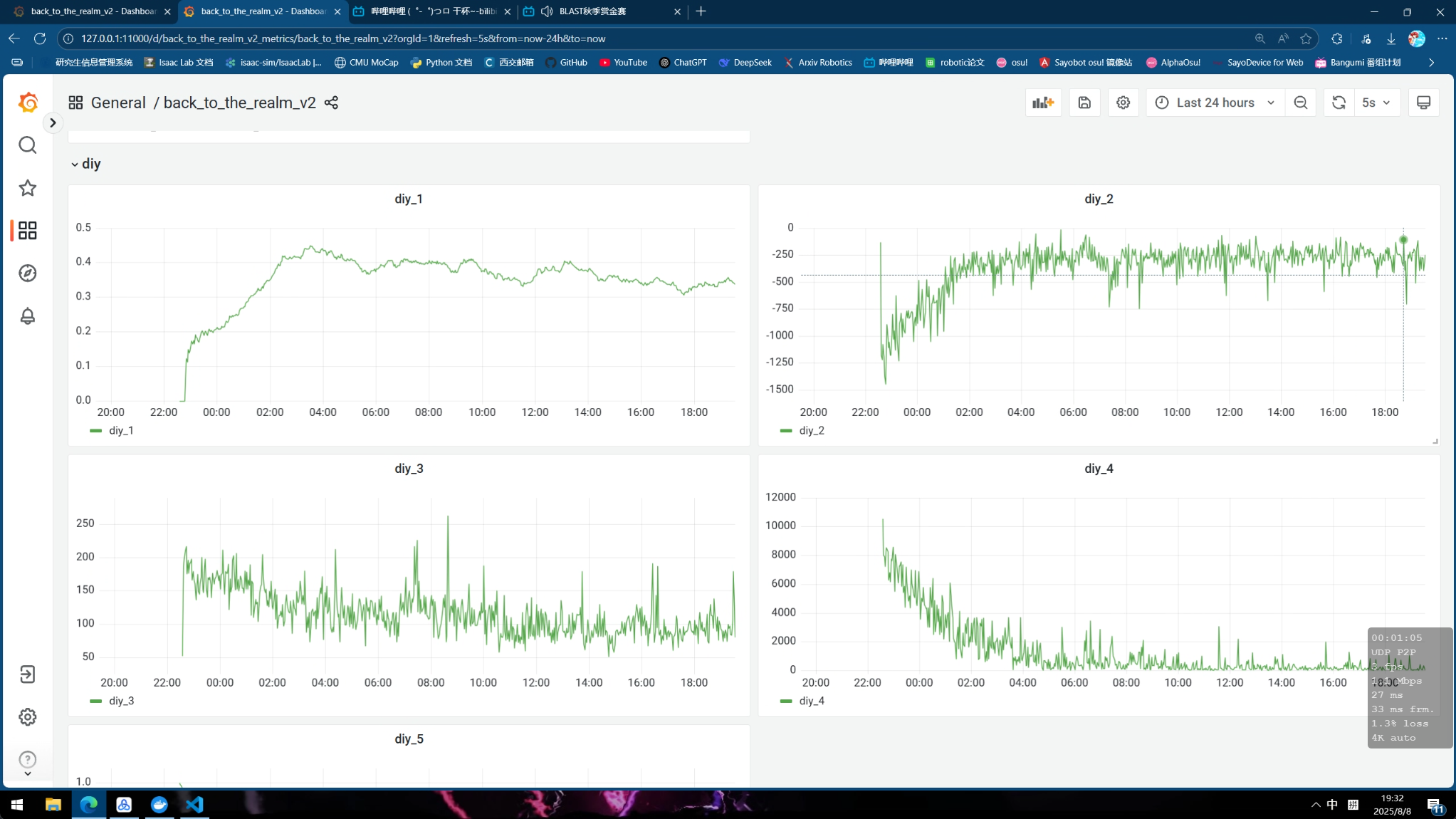
下面为成功训练出来的一些曲线, 其中diy信息分别表示:
- diy_1: 胜率
- diy_2: 一个episode总奖励
- diy_3: 一个episode撞墙总次数
- diy_4: 一个episode未探索的区域大小
- diy_5: DQN的探索系数epsilon
v1.1 wyh训练40h 具身, target_dqn, cnn, buffsize 1e5, gamma=0.9 代码版本2025 prelim v1.1
| part1 | part2 |
|---|---|
 |
 |
v1.3 ghw训练20h 具身, ddqn, cnn, buffsize 1e6, gamma=0.995 代码版本2025 prelim v1.1
| part1 | part2 |
|---|---|
 |
 |
v1.2 wty训练40h 王者, target_dqn, cnn, buffsize 1e6, gamma=0.9 代码版本2025 prelim v1.2
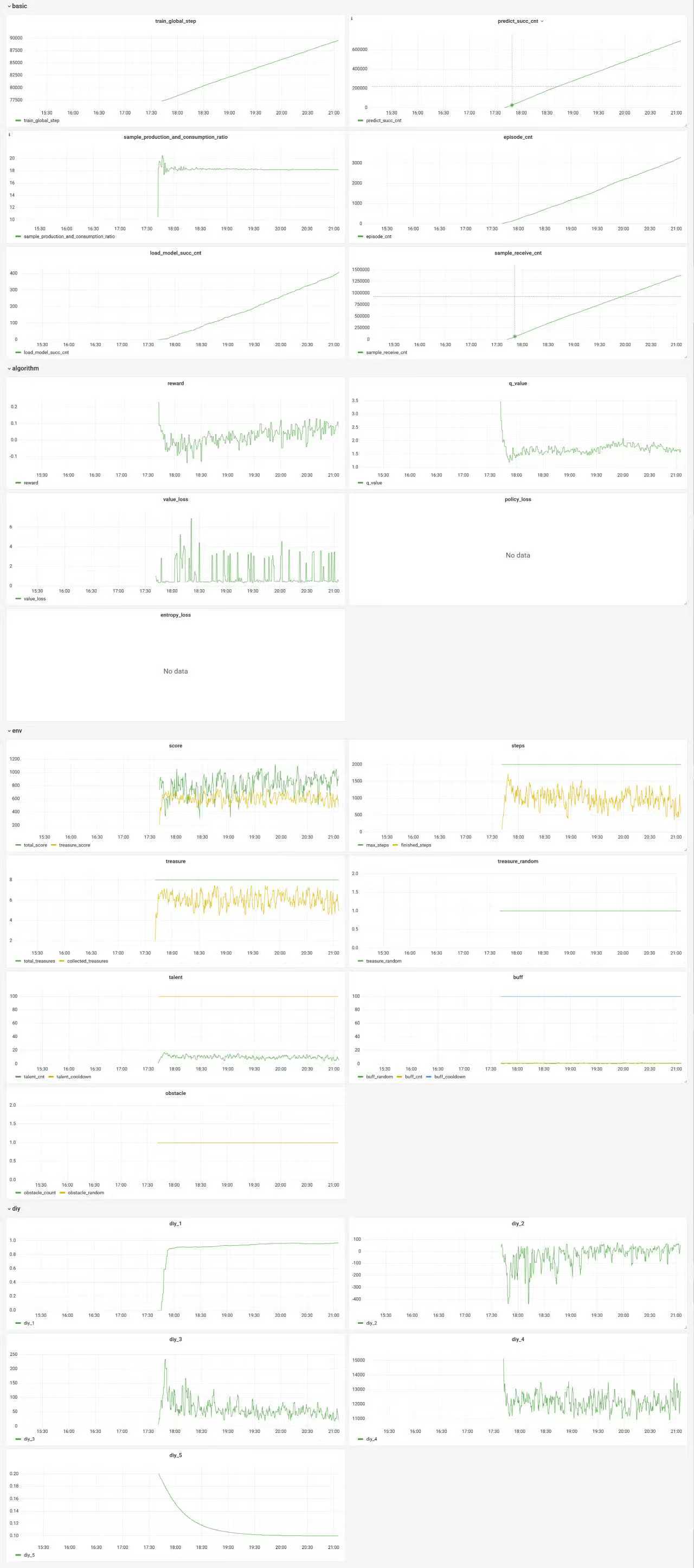
v1.1 wty训练26h 王者, target_dqn, cnn, buffsize 1e5, gamma=0.9 代码版本2025 prelim v1.1
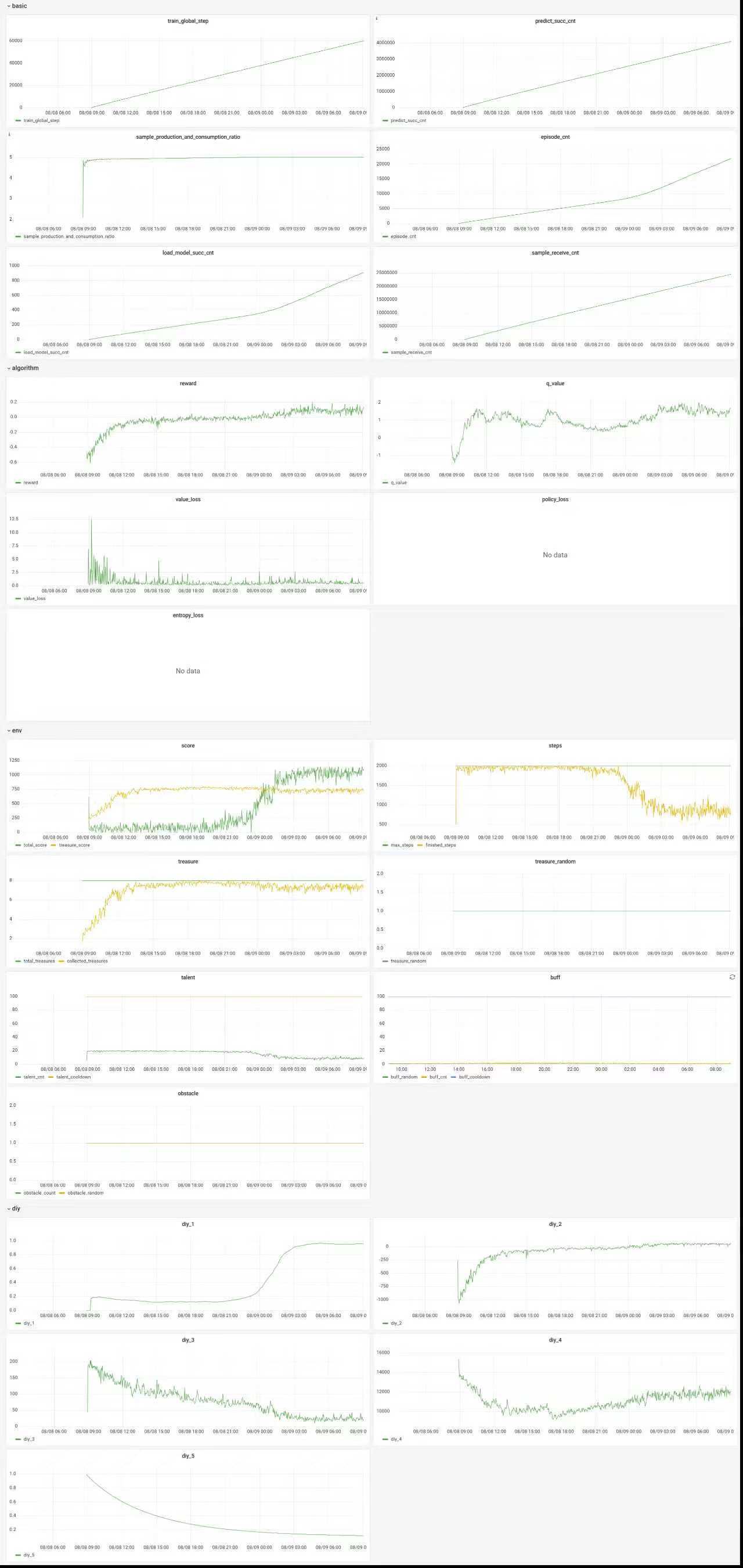
注意: 一定要将sample_production_and_consumption_ratio控制在10以下
问题:
- v1.1最后总是少一个宝箱
- v1.2最后会少很多宝箱
- v1.3前期捡到所有宝箱速度很快,但最后无法走到终点
代码架构
这里我们只在target_dqn上进行了成功的修改, 这里仅介绍该算法架构
code
├── agent_target_dqn
│ ├── agent.py # 智能体
│ ├── algorithm # 算法
│ │ ├── algorithm_ddqn.py # ddqn
│ │ └── algorithm.py # ddqn + simba v2
│ ├── conf # 配置
│ │ ├── conf.py # 算法配置, 奖励系数配置
│ │ ├── constants.py # 一些常量
│ │ ├── train_env_conf_fixed.toml # 固定的环境配置 (用于测试, 固定起点, 终点, 8个宝箱)
│ │ └── train_env_conf.toml # 随机的训练环境配置
│ ├── feature # 特征处理
│ │ ├── definition.py # 基础定义
│ │ └── state_manager.py # OrganManager管理物件位置信息, MapManager管理地图信息, StateManager处理得到obs, reward
│ ├── model # 模型
│ │ ├── model_cnn.py # CNN+MLP模型
│ │ ├── model.py # CNN+simbaV2模型
│ │ └── simbaV2/ # simbaV2相关函数
│ ├── utils/ # 处理保存调试文件
│ └── workflow # 工作流
│ └── train_workflow.py # aisrv训练的工作流代码
├── conf
│ ├── configure_app.toml # 全局训练的train_sleep_time, replay_buffer_capacity等信息配置
│ └── ...
└── train_test.py # 测试当前代码能否启动注意
本次比赛总结一些值得注意的内容:
sample_production_and_consumption_ratio不能过高, 根据开启的并行环境数, 和电脑的性能, 自行调整configure_app.toml中的train_sleep_time来降低 (虽然导致训练变慢, 但是训练效果更好)- 先从简单奖励开始测试算法可行性 (例如官方给的ppo就不知道为什么训练不出来), 模型的训练效率, 例如可以先单独只开不撞墙奖励, 训练10mins左右模型就会收敛到一个不撞墙策略上, 而对模型加入残差和layernorm就会导致30mins都不收敛
- 先要一开始跑出一个能用的算法、奖励、模型先,在一个可以训出来的奖励上慢慢加内容
- 最后总存在宝箱无法捡完的问题,而且还有明显的重复路径,可能奖励设计还是有问题,需要改进
最终排名,王者前70名进入复赛,具身前50名进入复赛:


p.s. 最后结束王者的v1.1才训练出来,估计能排到20多名位置,所以应该还有很多优化空间